 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Feature Diversity Necessary in Neural Network Initialization?
Paper and Code
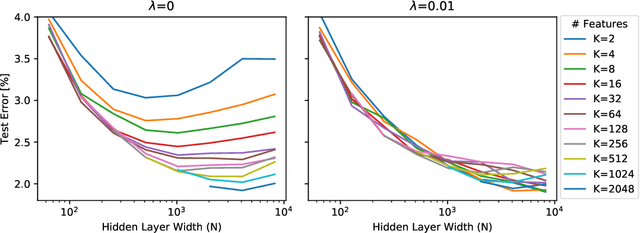
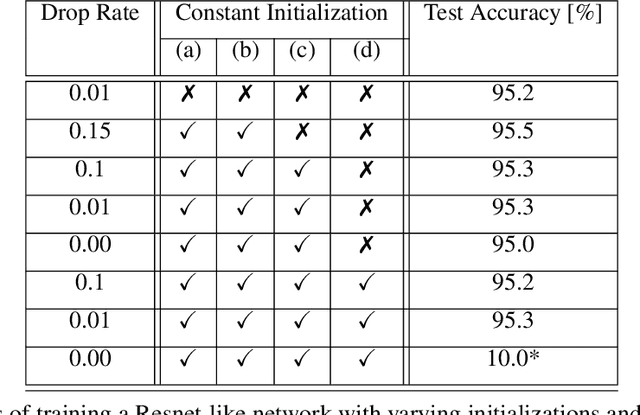
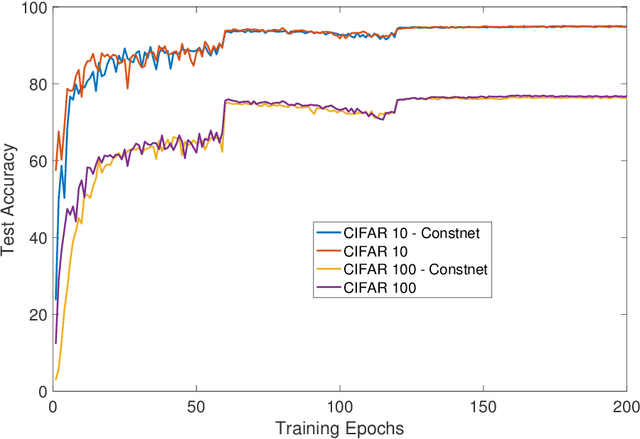
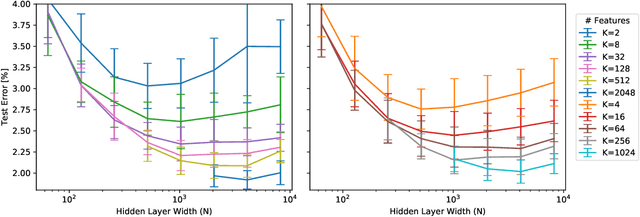
Standard practice in training neural networks involves initializing the weights in an independent fashion. The results of recent work suggest that feature "diversity" at initialization plays an important role in training the network. However, other initialization schemes with reduced feature diversity have also been shown to be viable. In this work, we conduct a series of experiments aimed at elucidating the importance of feature diversity at initialization. We show that a complete lack of diversity is harmful to training, but its effects can be counteracted by a relatively small addition of noise - even the noise in standard non-deterministic GPU computations is sufficient. Furthermore, we construct a deep convolutional network with identical features at initialization and almost all of the weights initialized at 0 that can be trained to reach accuracy matching its standard-initialized counterpart.