 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Continual Learning Truly Learning Representations Continually?
Paper and Code
Jun 16, 2022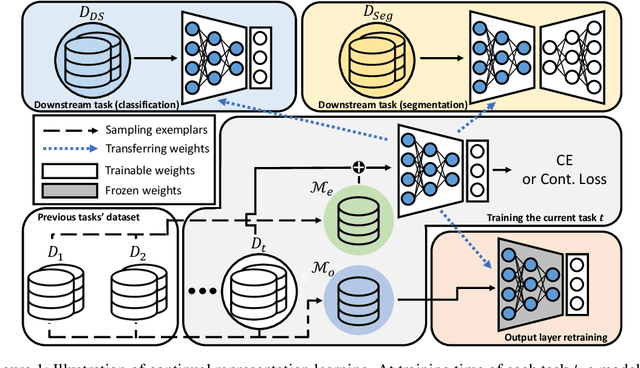
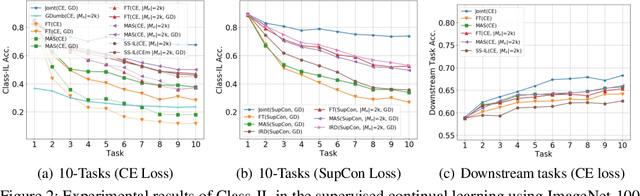
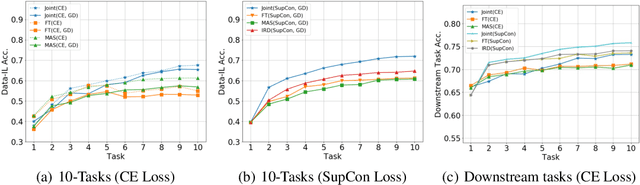
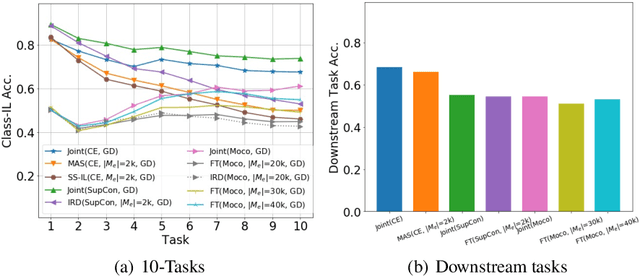
Continual learning (CL) aims to learn from sequentially arriving tasks without forgetting previous tasks. Whereas CL algorithms have tried to achieve higher average test accuracy across all the tasks learned so far, learning continuously useful representations is critical for successful generalization and downstream transfer. To measure representational quality, we re-train only the output layers using a small balanced dataset for all the tasks, evaluating the average accuracy without any biased predictions toward the current task. We also test on several downstream tasks, measuring transfer learning accuracy of the learned representations. By testing our new formalism on ImageNet-100 and ImageNet-1000, we find that using more exemplar memory is the only option to make a meaningful difference in learned representations, and most of the regularization- or distillation-based CL algorithms that use the exemplar memory fail to learn continuously useful representations in class-incremental learning. Surprisingly, unsupervised (or self-supervised) CL with sufficient memory size can achieve comparable performance to the supervised counterparts. Considering non-trivial labeling costs, we claim that finding more efficient unsupervised CL algorithms that minimally use exemplary memory would be the next promising direction for CL research.