 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRISformer: Dense Vision Transformers for Single-Image Inverse Rendering in Indoor Scenes
Paper and Code
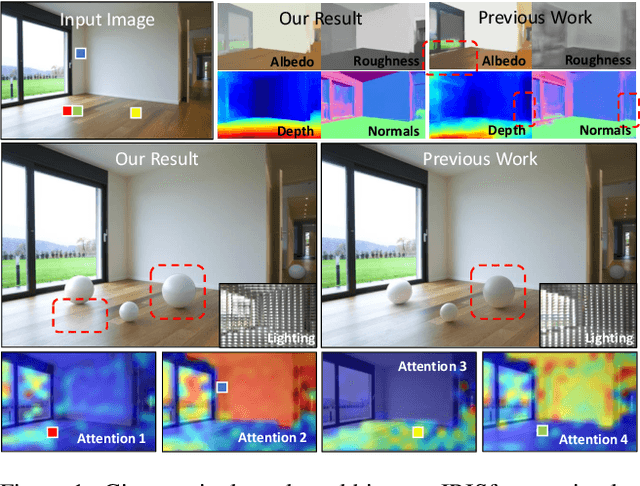
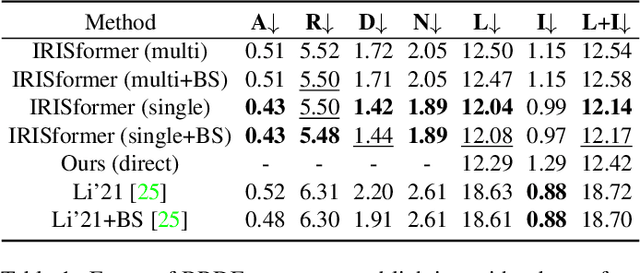

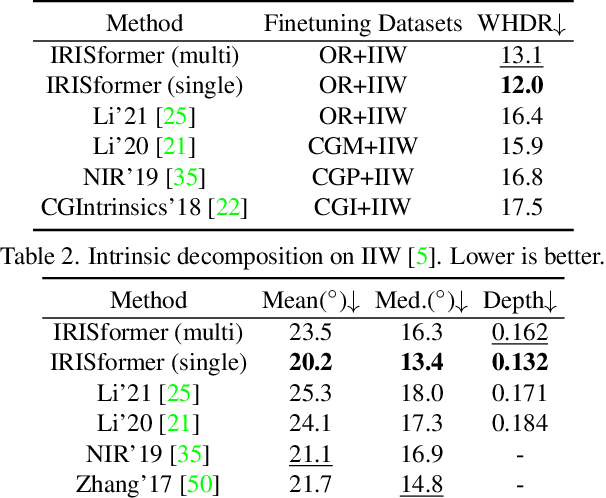
Indoor scenes exhibit significant appearance variations due to myriad interactions between arbitrarily diverse object shapes, spatially-changing materials, and complex lighting. Shadows, highlights, and inter-reflections caused by visible and invisible light sources require reasoning about long-range interactions for inverse rendering, which seeks to recover the components of image formation, namely, shape, material, and lighting. In this work, our intuition is that the long-range attention learned by transformer architectures is ideally suited to solve longstanding challenges in single-image inverse rendering. We demonstrate with a specific instantiation of a dense vision transformer, IRISformer, that excels at both single-task and multi-task reasoning required for inverse rendering. Specifically, we propose a transformer architecture to simultaneously estimate depths, normals, spatially-varying albedo, roughness and lighting from a single image of an indoor scene. Our extensive evaluations on benchmark datasets demonstrate state-of-the-art results on each of the above tasks, enabling applications like object insertion and material editing in a single unconstrained real image, with greater photorealism than prior works. Code and data are publicly released at https://github.com/ViLab-UCSD/IRISformer.