 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPDAE: Improved Patch-Based Deep Autoencoder for Lossy Point Cloud Geometry Compression
Paper and Code
Aug 04, 2022


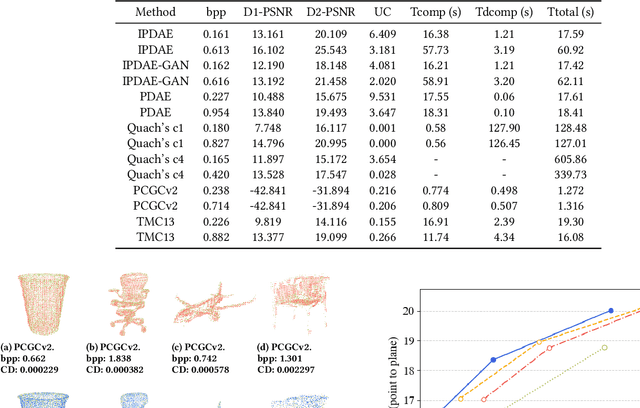
Point cloud is a crucial representation of 3D contents, which has been widely used in many areas such as virtual reality, mixed reality, autonomous driving, etc. With the boost of the number of points in the data, how to efficiently compress point cloud becomes a challenging problem. In this paper, we propose a set of significant improvements to patch-based point cloud compression, i.e., a learnable context model for entropy coding, octree coding for sampling centroid points, and an integrated compression and training process. In addition, we propose an adversarial network to improve the uniformity of points during reconstruction. Our experiments show that the improved patch-based autoencoder outperforms the state-of-the-art in terms of rate-distortion performance, on both sparse and large-scale point clouds. More importantly, our method can maintain a short compression time while ensuring the reconstruction quality.