 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Language Impact in Bilingual Approaches for Computational Language Documentation
Paper and Code
Mar 30, 2020


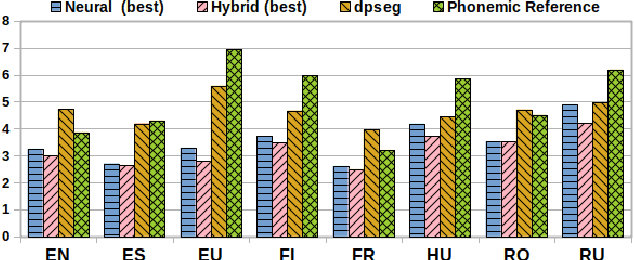
For endangered languages, data collection campaigns have to accommodate the challenge that many of them are from oral tradition, and producing transcriptions is costly. Therefore, it is fundamental to translate them into a widely spoken language to ensure interpretability of the recordings. In this paper we investigate how the choice of translation language affects the posterior documentation work and potential automatic approaches which will work on top of the produced bilingual corpus. For answering this question, we use the MaSS multilingual speech corpus (Boito et al., 2020) for creating 56 bilingual pairs that we apply to the task of low-resource unsupervised word segmentation and alignment. Our results highlight that the choice of language for translation influences the word segmentation performance, and that different lexicons are learned by using different aligned translations. Lastly, this paper proposes a hybrid approach for bilingual word segmentation, combining boundary clues extracted from a non-parametric Bayesian model (Goldwater et al., 2009a) with the attentional word segmentation neural model from Godard et al. (2018). Our results suggest that incorporating these clues into the neural models' input representation increases their translation and alignment quality, specially for challenging language pairs.