 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Bias and Fairness in Facial Expression Recognition
Paper and Code
Aug 21, 2020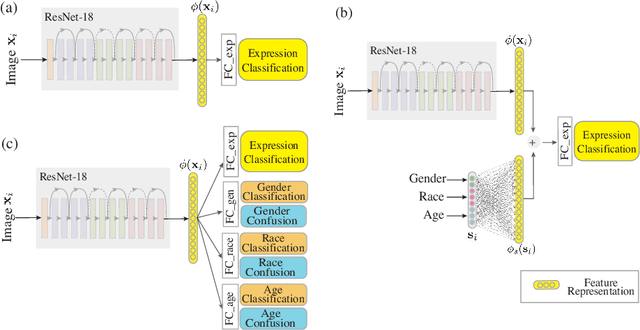
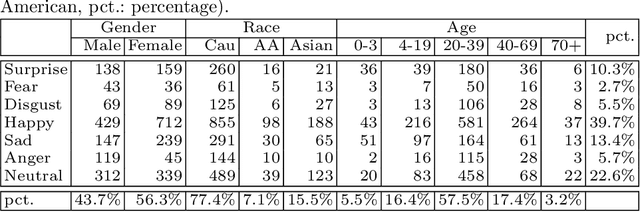
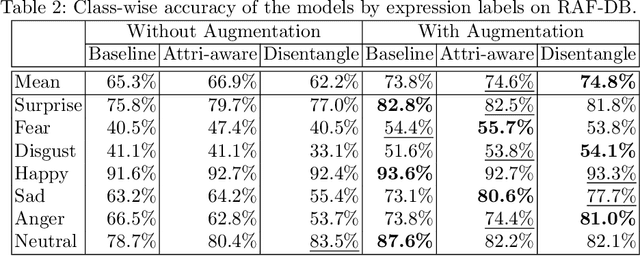
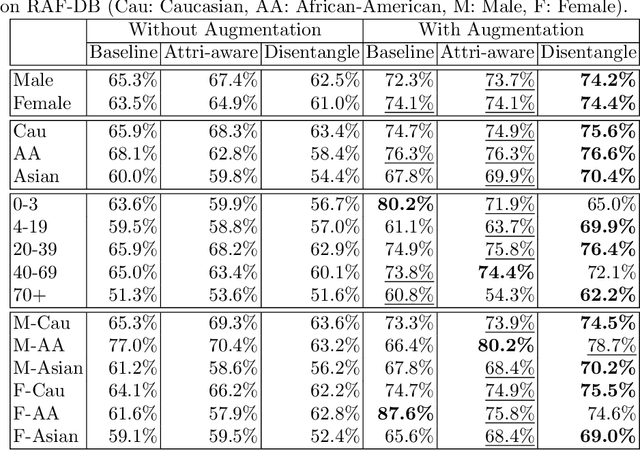
Recognition of expressions of emotions and affect from facial images is a well-studied research problem in the fields of affective computing and computer vision with a large number of datasets available containing facial images and corresponding expression labels. However, virtually none of these datasets have been acquired with consideration of fair distribution across the human population. Therefore, in this work, we undertake a systematic investigation of bias and fairness in facial expression recognition by comparing three different approaches, namely a baseline, an attribute-aware and a disentangled approach, on two well-known datasets, RAF-DB and CelebA. Our results indicate that: (i) data augmentation improves the accuracy of the baseline model, but this alone is unable to mitigate the bias effect; (ii) both the attribute-aware and the disentangled approaches fortified with data augmentation perform better than the baseline approach in terms of accuracy and fairness; (iii) the disentangled approach is the best for mitigating demographic bias; and (iv) the bias mitigation strategies are more suitable in the existence of uneven attribute distribution or imbalanced number of subgroup data.