 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-Modal Constraint Loss For Image-Text Retrieval
Paper and Code

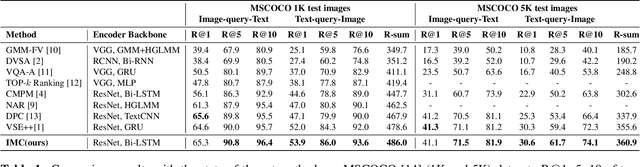
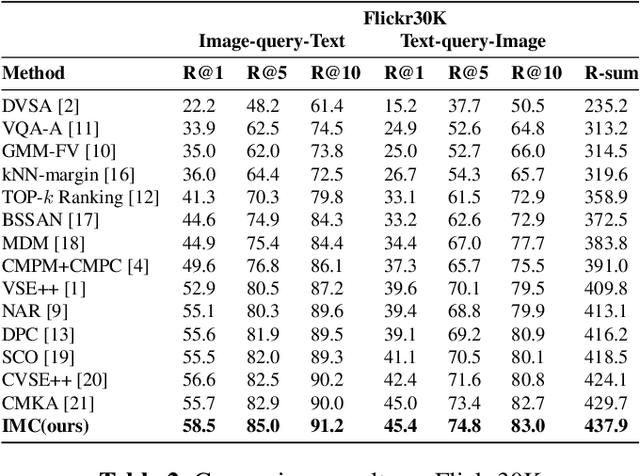
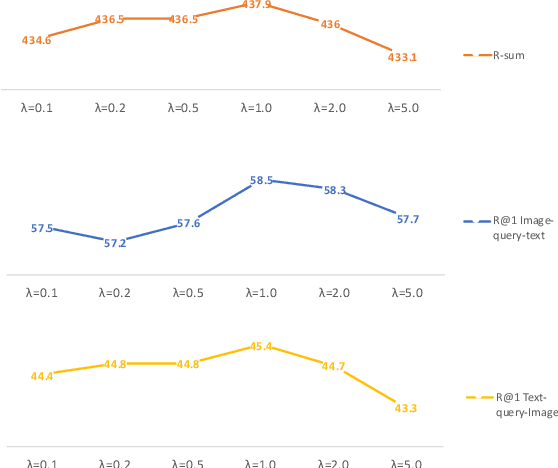
Cross-modal retrieval has drawn much attention in both computer vision and natural language processing domains. With the development of convolutional and recurrent neural networks, the bottleneck of retrieval across image-text modalities is no longer the extraction of image and text features but an efficient loss function learning in embedding space. Many loss functions try to closer pairwise features from heterogeneous modalities. This paper proposes a method for learning joint embedding of images and texts using an intra-modal constraint loss function to reduce the violation of negative pairs from the same homogeneous modality. Experimental results show that our approach outperforms state-of-the-art bi-directional image-text retrieval methods on Flickr30K and Microsoft COCO datasets. Our code is publicly available: https://github.com/CanonChen/IMC.