 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting GNN-based IDS Detections Using Provenance Graph Structural Features
Paper and Code

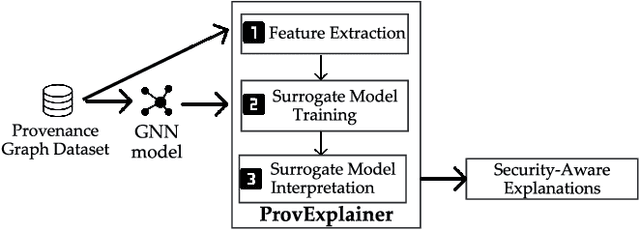
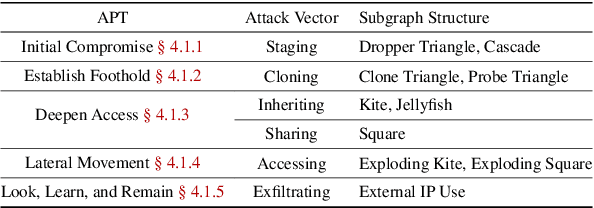
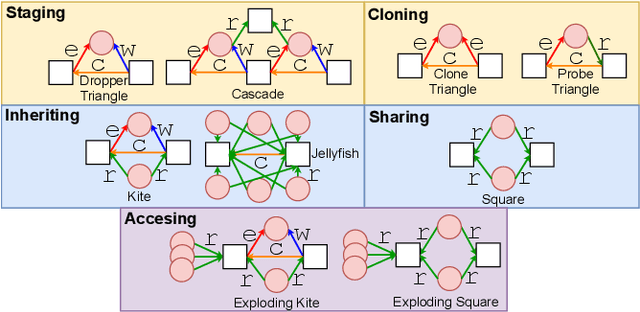
The black-box nature of complex Neural Network (NN)-based models has hindered their widespread adoption in security domains due to the lack of logical explanations and actionable follow-ups for their predictions. To enhance the transparency and accountability of Graph Neural Network (GNN) security models used in system provenance analysis, we propose PROVEXPLAINER, a framework for projecting abstract GNN decision boundaries onto interpretable feature spaces. We first replicate the decision-making process of GNNbased security models using simpler and explainable models such as Decision Trees (DTs). To maximize the accuracy and fidelity of the surrogate models, we propose novel graph structural features founded on classical graph theory and enhanced by extensive data study with security domain knowledge. Our graph structural features are closely tied to problem-space actions in the system provenance domain, which allows the detection results to be explained in descriptive, human language. PROVEXPLAINER allowed simple DT models to achieve 95% fidelity to the GNN on program classification tasks with general graph structural features, and 99% fidelity on malware detection tasks with a task-specific feature package tailored for direct interpretation. The explanations for malware classification are demonstrated with case studies of five real-world malware samples across three malware families.