 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter Extreme Points Geodesics for Weakly Supervised Segmentation
Paper and Code
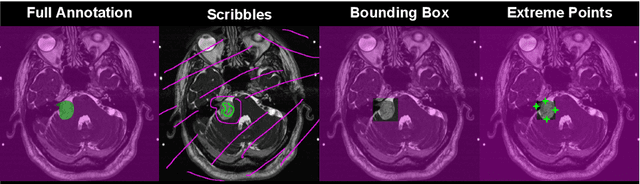
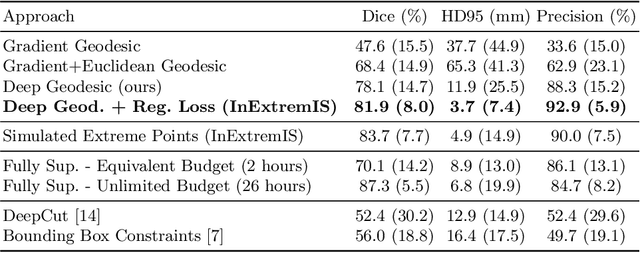
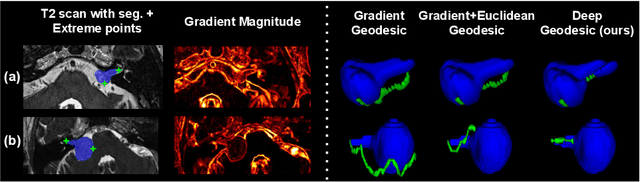
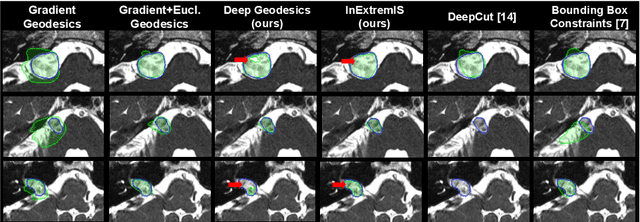
We introduce $\textit{InExtremIS}$, a weakly supervised 3D approach to train a deep image segmentation network using particularly weak train-time annotations: only 6 extreme clicks at the boundary of the objects of interest. Our fully-automatic method is trained end-to-end and does not require any test-time annotations. From the extreme points, 3D bounding boxes are extracted around objects of interest. Then, deep geodesics connecting extreme points are generated to increase the amount of "annotated" voxels within the bounding boxes. Finally, a weakly supervised regularised loss derived from a Conditional Random Field formulation is used to encourage prediction consistency over homogeneous regions. Extensive experiments are performed on a large open dataset for Vestibular Schwannoma segmentation. $\textit{InExtremIS}$ obtained competitive performance, approaching full supervision and outperforming significantly other weakly supervised techniques based on bounding boxes. Moreover, given a fixed annotation time budget, $\textit{InExtremIS}$ outperforms full supervision. Our code and data are available online.