 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Based Model Adaptation For Direct Speech Translation
Paper and Code
Oct 23, 2019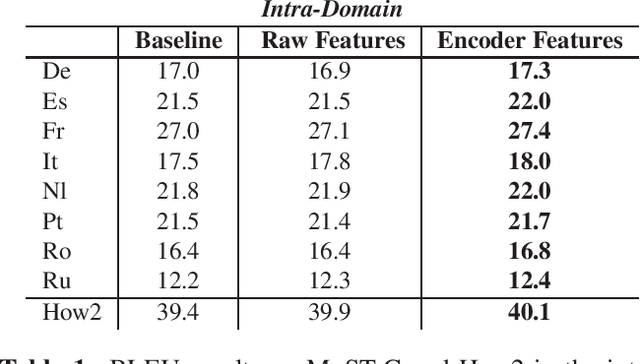
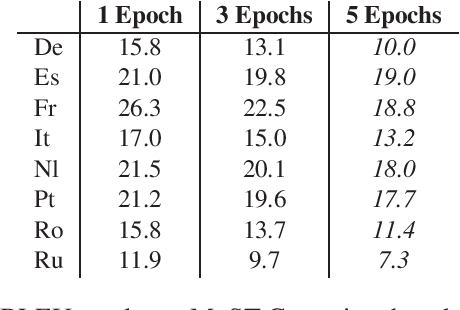
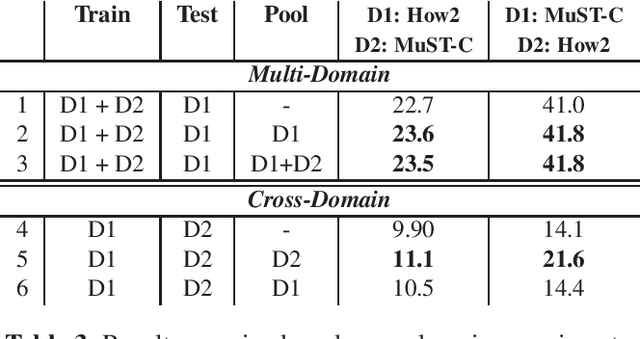
Despite recent technology advancements, the effectiveness of neural approaches to end-to-end speech-to-text translation is still limited by the paucity of publicly available training corpora. We tackle this limitation with a method to improve data exploitation and boost the system's performance at inference time. Our approach allows us to customize "on the fly" an existing model to each incoming translation request. At its core, it exploits an instance selection procedure to retrieve, from a given pool of data, a small set of samples similar to the input query in terms of latent properties of its audio signal. The retrieved samples are then used for an instance-specific fine-tuning of the model. We evaluate our approach in three different scenarios. In all data conditions (different languages, in/out-of-domain adaptation), our instance-based adaptation yields coherent performance gains over static models.