Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Theoretically Aided Reinforcement Learning for Embodied Agents
Paper and Code
May 31, 2016
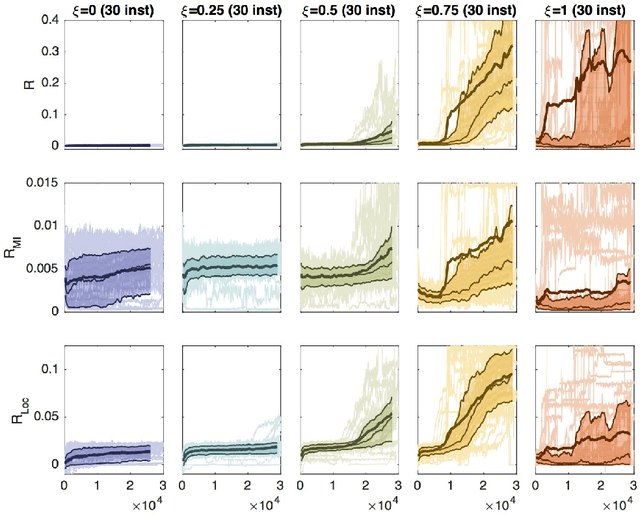
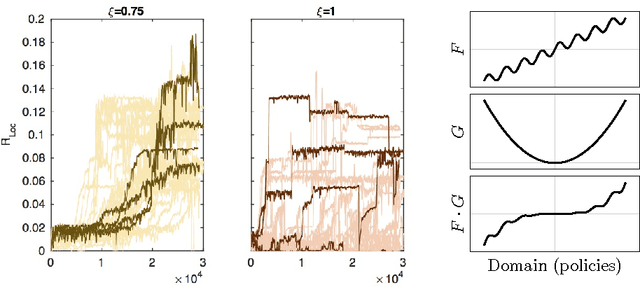
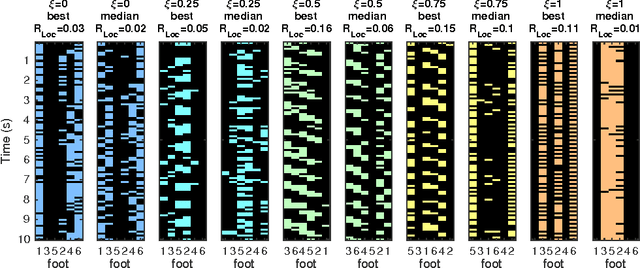
Reinforcement learning for embodied agents is a challenging problem. The accumulated reward to be optimized is often a very rugged function, and gradient methods are impaired by many local optimizers. We demonstrate, in an experimental setting, that incorporating an intrinsic reward can smoothen the optimization landscape while preserving the global optimizers of interest. We show that policy gradient optimization for locomotion in a complex morphology is significantly improved when supplementing the extrinsic reward by an intrinsic reward defined in terms of the mutual information of time consecutive sensor readings.
* 10 pages, 4 figures, 8 pages appendix
View paper on