Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Theoretic Limits for Linear Prediction with Graph-Structured Sparsity
Paper and Code
May 06, 2017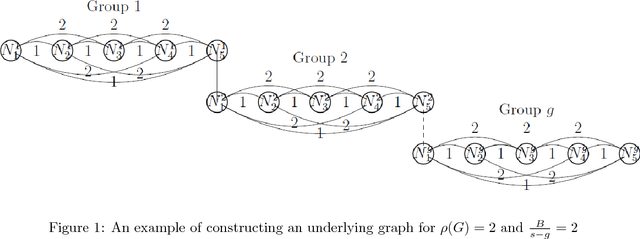
We analyze the necessary number of samples for sparse vector recovery in a noisy linear prediction setup. This model includes problems such as linear regression and classification. We focus on structured graph models. In particular, we prove that sufficient number of samples for the weighted graph model proposed by Hegde and others is also necessary. We use the Fano's inequality on well constructed ensembles as our main tool in establishing information theoretic lower bounds.
View paper on