Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Biases for Object-Centric Representations in the Presence of Complex Textures
Paper and Code
Apr 26, 2022

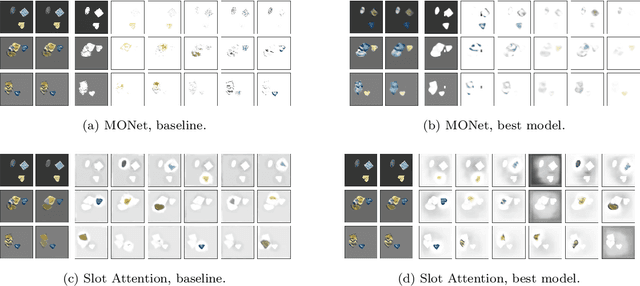

Understanding which inductive biases could be helpful for the unsupervised learning of object-centric representations of natural scenes is challenging. We use neural style transfer to generate datasets where objects have complex textures while still retaining ground-truth annotations. We find that methods that use a single module to reconstruct both the shape and visual appearance of each object learn more useful representations and achieve better object separation. In addition, we observe that adjusting the latent space size is not sufficient to improve segmentation performance. Finally, the downstream usefulness of the representations is significantly more strongly correlated with segmentation quality than with reconstruction accuracy.
View paper on
 OpenReview
OpenReview