 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Real-world Noisy Speech in Neural-network-based Speech Enhancement Systems
Paper and Code
Sep 21, 2021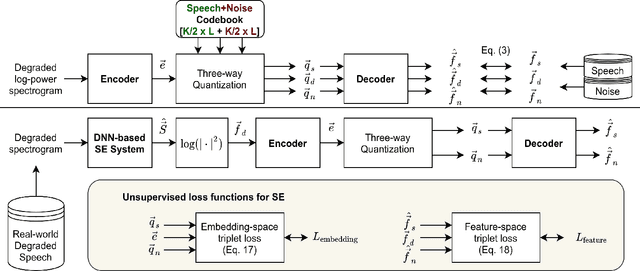

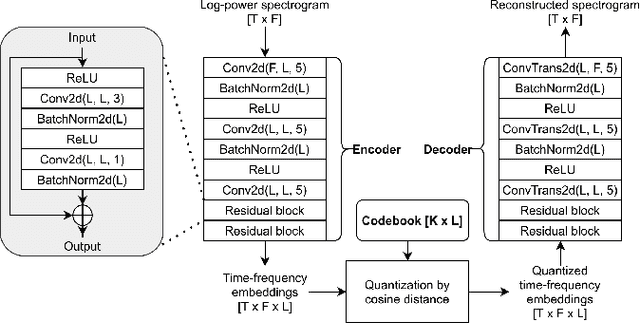
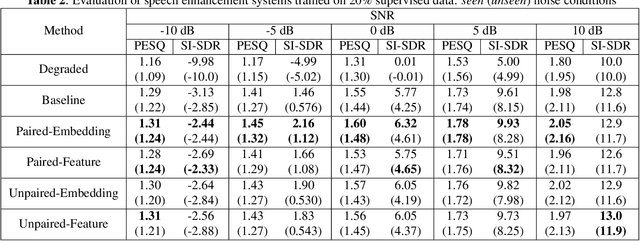
Supervised speech enhancement relies on parallel databases of degraded speech signals and their clean reference signals during training. This setting prohibits the use of real-world degraded speech data that may better represent the scenarios where such systems are used. In this paper, we explore methods that enable supervised speech enhancement systems to train on real-world degraded speech data. Specifically, we propose a semi-supervised approach for speech enhancement in which we first train a modified vector-quantized variational autoencoder that solves a source separation task. We then use this trained autoencoder to further train an enhancement network using real-world noisy speech data by computing a triplet-based unsupervised loss function. Experiments show promising results for incorporating real-world data in training speech enhancement systems.