Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncluding Dialects and Language Varieties in Author Profiling
Paper and Code
Jul 03, 2017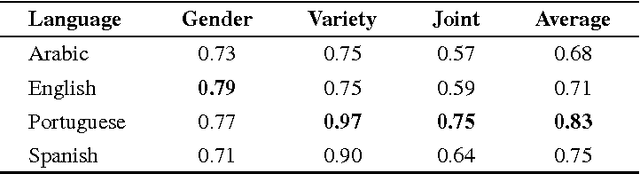


This paper presents a computational approach to author profiling taking gender and language variety into account. We apply an ensemble system with the output of multiple linear SVM classifiers trained on character and word $n$-grams. We evaluate the system using the dataset provided by the organizers of the 2017 PAN lab on author profiling. Our approach achieved 75% average accuracy on gender identification on tweets written in four languages and 97% accuracy on language variety identification for Portuguese.
* Proceedings of PAN at CLEF 2017
View paper on