Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn deep reinforcement learning, a pruned network is a good network
Paper and Code
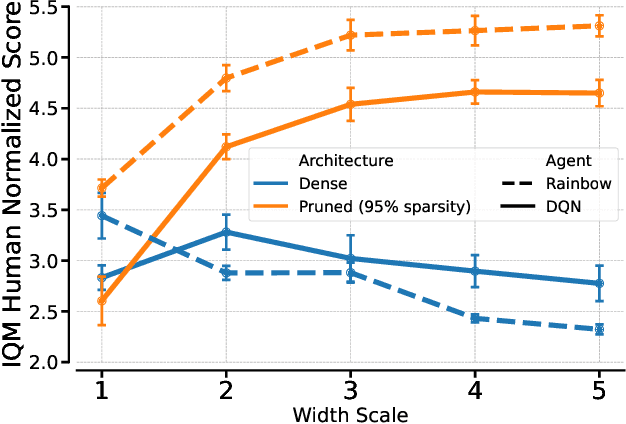
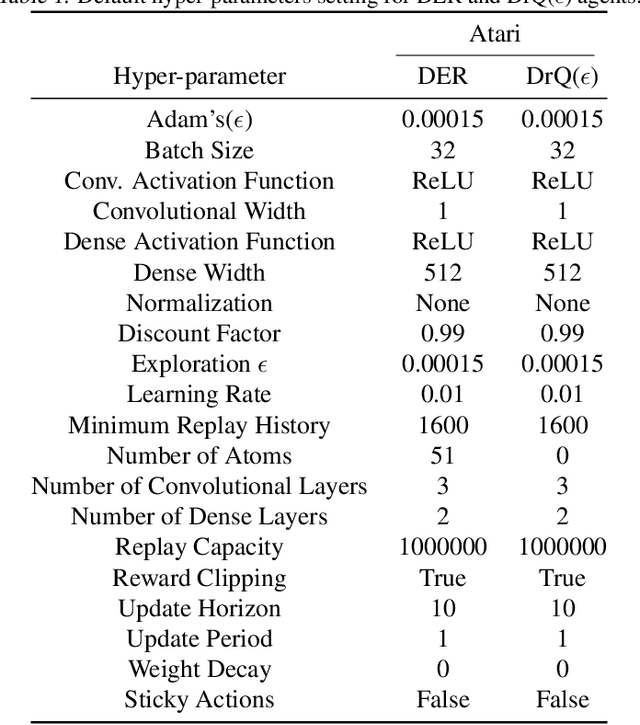
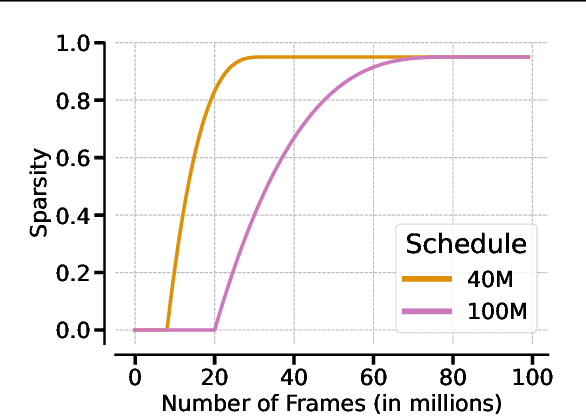
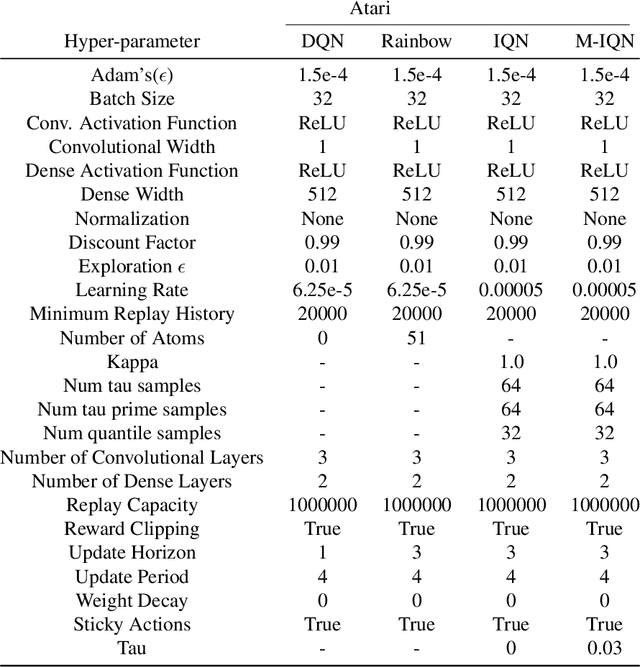
Recent work has shown that deep reinforcement learning agents have difficulty in effectively using their network parameters. We leverage prior insights into the advantages of sparse training techniques and demonstrate that gradual magnitude pruning enables agents to maximize parameter effectiveness. This results in networks that yield dramatic performance improvements over traditional networks and exhibit a type of "scaling law", using only a small fraction of the full network parameters.
View paper on