 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Speech Enhancement Network by Learning Audio-visual Affinity with Multi-head Attention
Paper and Code
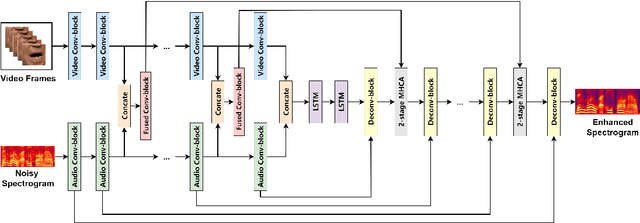
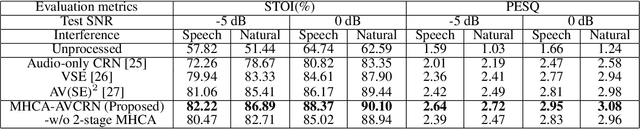
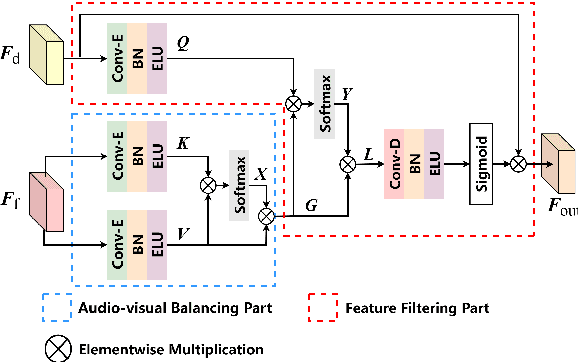

Audio-visual speech enhancement system is regarded as one of promising solutions for isolating and enhancing speech of desired speaker. Typical methods focus on predicting clean speech spectrum via a naive convolution neural network based encoder-decoder architecture, and these methods a) are not adequate to use data fully, b) are unable to effectively balance audio-visual features. The proposed model alleviates these drawbacks by a) applying a model that fuses audio and visual features layer by layer in encoding phase, and that feeds fused audio-visual features to each corresponding decoder layer, and more importantly, b) introducing a 2-stage multi-head cross attention (MHCA) mechanism to infer audio-visual speech enhancement for balancing the fused audio-visual features and eliminating irrelevant features. This paper proposes attentional audio-visual multi-layer feature fusion model, in which MHCA units are applied to feature mapping at every layer of decoder. The proposed model demonstrates the superior performance of the network against the state-of-the-art models.