 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving video retrieval using multilingual knowledge transfer
Paper and Code
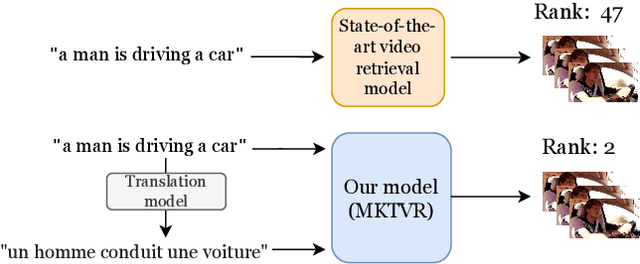
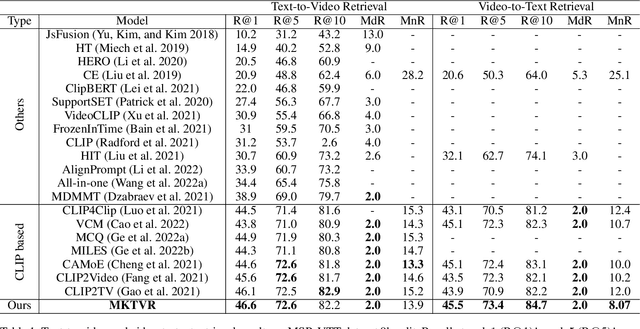
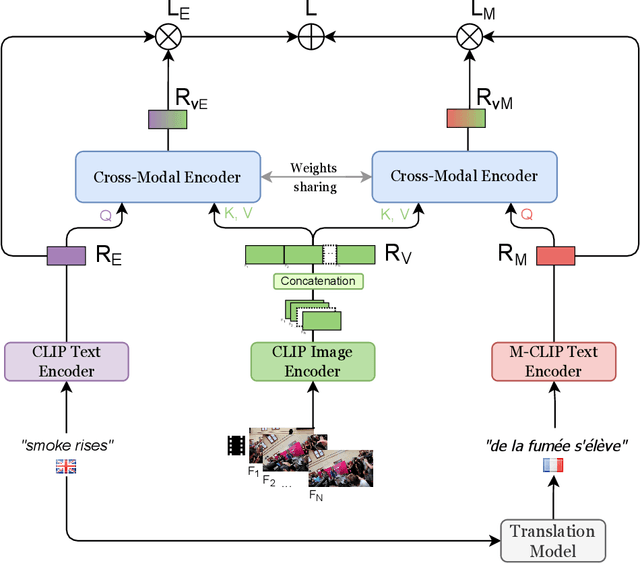
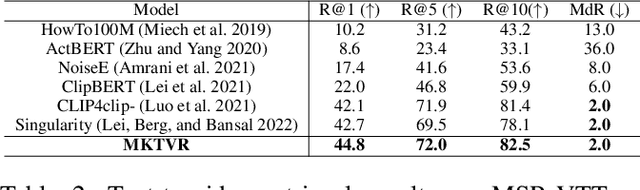
Video retrieval has seen tremendous progress with the development of vision-language models. However, further improving these models require additional labelled data which is a huge manual effort. In this paper, we propose a framework MKTVR, that utilizes knowledge transfer from a multilingual model to boost the performance of video retrieval. We first use state-of-the-art machine translation models to construct pseudo ground-truth multilingual video-text pairs. We then use this data to learn a video-text representation where English and non-English text queries are represented in a common embedding space based on pretrained multilingual models. We evaluate our proposed approach on four English video retrieval datasets such as MSRVTT, MSVD, DiDeMo and Charades. Experimental results demonstrate that our approach achieves state-of-the-art results on all datasets outperforming previous models. Finally, we also evaluate our model on a multilingual video-retrieval dataset encompassing six languages and show that our model outperforms previous multilingual video retrieval models in a zero-shot setting.