 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization of Deep Reinforcement Learning-based TSP Solvers
Paper and Code
Oct 06, 2021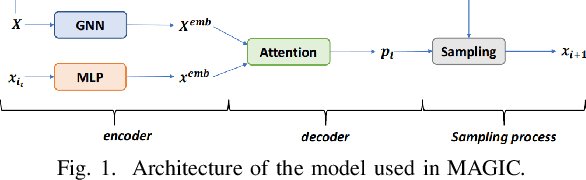
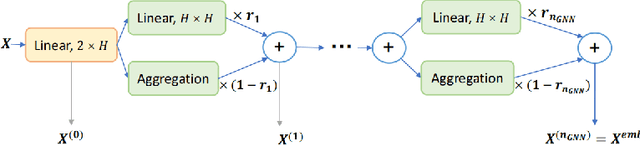
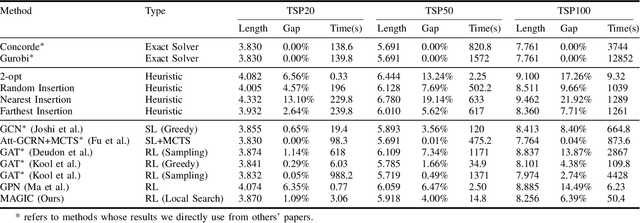
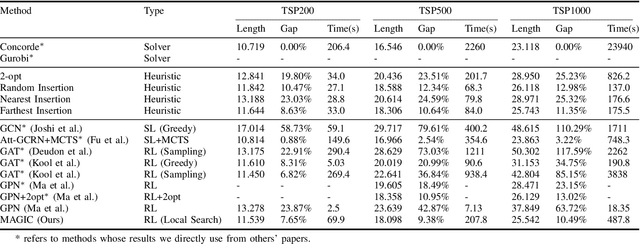
Recent work applying deep reinforcement learning (DRL) to solve traveling salesman problems (TSP) has shown that DRL-based solvers can be fast and competitive with TSP heuristics for small instances, but do not generalize well to larger instances. In this work, we propose a novel approach named MAGIC that includes a deep learning architecture and a DRL training method. Our architecture, which integrates a multilayer perceptron, a graph neural network, and an attention model, defines a stochastic policy that sequentially generates a TSP solution. Our training method includes several innovations: (1) we interleave DRL policy gradient updates with local search (using a new local search technique), (2) we use a novel simple baseline, and (3) we apply curriculum learning. Finally, we empirically demonstrate that MAGIC is superior to other DRL-based methods on random TSP instances, both in terms of performance and generalizability. Moreover, our method compares favorably against TSP heuristics and other state-of-the-art approach in terms of performance and computational time.