 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deliberation by Text-Only and Semi-Supervised Training
Paper and Code
Jun 29, 2022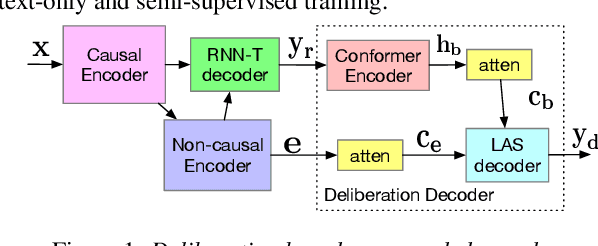
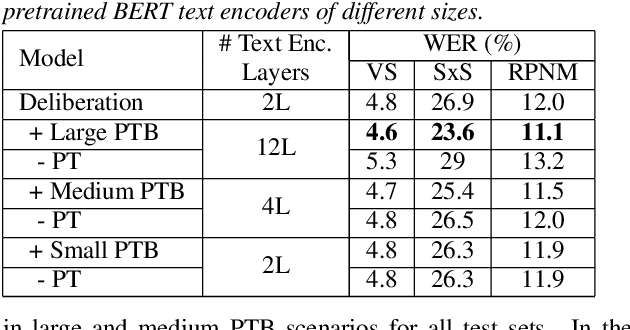

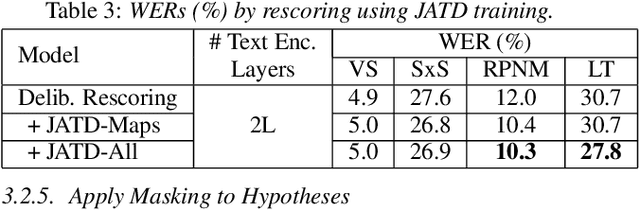
Text-only and semi-supervised training based on audio-only data has gained popularity recently due to the wide availability of unlabeled text and speech data. In this work, we propose incorporating text-only and semi-supervised training into an attention-based deliberation model. By incorporating text-only data in training a bidirectional encoder representation from transformer (BERT) for the deliberation text encoder, and large-scale text-to-speech and audio-only utterances using joint acoustic and text decoder (JATD) and semi-supervised training, we achieved 4%-12% WER reduction for various tasks compared to the baseline deliberation. Compared to a state-of-the-art language model (LM) rescoring method, the deliberation model reduces the Google Voice Search WER by 11% relative. We show that the deliberation model also achieves a positive human side-by-side evaluation compared to the state-of-the-art LM rescorer with reasonable endpointer latencies.