 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving and Diagnosing Knowledge-Based Visual Question Answering via Entity Enhanced Knowledge Injection
Paper and Code



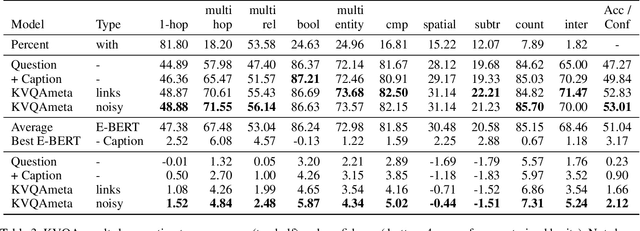
Knowledge-Based Visual Question Answering (KBVQA) is a bi-modal task requiring external world knowledge in order to correctly answer a text question and associated image. Recent single modality text work has shown knowledge injection into pre-trained language models, specifically entity enhanced knowledge graph embeddings, can improve performance on downstream entity-centric tasks. In this work, we empirically study how and whether such methods, applied in a bi-modal setting, can improve an existing VQA system's performance on the KBVQA task. We experiment with two large publicly available VQA datasets, (1) KVQA which contains mostly rare Wikipedia entities and (2) OKVQA which is less entity-centric and more aligned with common sense reasoning. Both lack explicit entity spans and we study the effect of different weakly supervised and manual methods for obtaining them. Additionally we analyze how recently proposed bi-modal and single modal attention explanations are affected by the incorporation of such entity enhanced representations. Our results show substantial improved performance on the KBVQA task without the need for additional costly pre-training and we provide insights for when entity knowledge injection helps improve a model's understanding. We provide code and enhanced datasets for reproducibility.