Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Bayesian Compression
Paper and Code
Dec 07, 2017

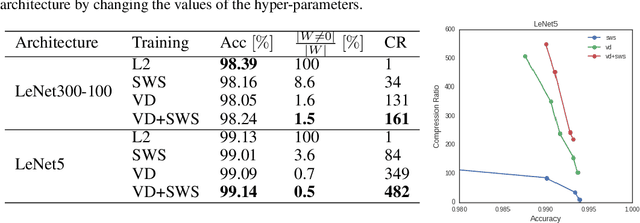
Compression of Neural Networks (NN) has become a highly studied topic in recent years. The main reason for this is the demand for industrial scale usage of NNs such as deploying them on mobile devices, storing them efficiently, transmitting them via band-limited channels and most importantly doing inference at scale. In this work, we propose to join the Soft-Weight Sharing and Variational Dropout approaches that show strong results to define a new state-of-the-art in terms of model compression.
View paper on