 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Temporal Differences
Paper and Code
Dec 21, 2014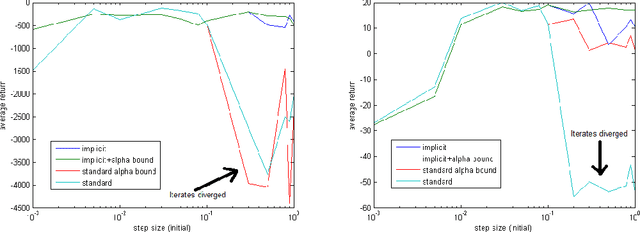
In reinforcement learning, the TD($\lambda$) algorithm is a fundamental policy evaluation method with an efficient online implementation that is suitable for large-scale problems. One practical drawback of TD($\lambda$) is its sensitivity to the choice of the step-size. It is an empirically well-known fact that a large step-size leads to fast convergence, at the cost of higher variance and risk of instability. In this work, we introduce the implicit TD($\lambda$) algorithm which has the same function and computational cost as TD($\lambda$), but is significantly more stable. We provide a theoretical explanation of this stability and an empirical evaluation of implicit TD($\lambda$) on typical benchmark tasks. Our results show that implicit TD($\lambda$) outperforms standard TD($\lambda$) and a state-of-the-art method that automatically tunes the step-size, and thus shows promise for wide applicability.