 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Cross-Lingual Rewarding for Efficient Multilingual Preference Alignment
Paper and Code
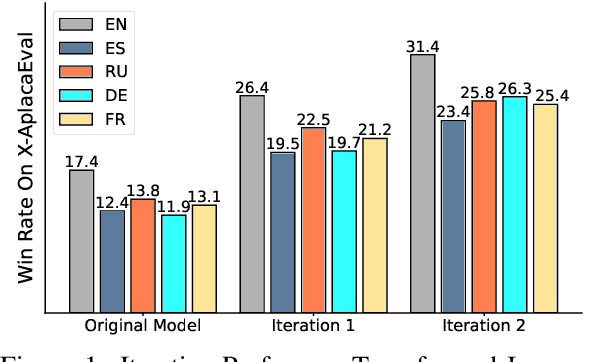



Direct Preference Optimization (DPO) has become a prominent method for aligning Large Language Models (LLMs) with human preferences. While DPO has enabled significant progress in aligning English LLMs, multilingual preference alignment is hampered by data scarcity. To address this, we propose a novel approach that $\textit{captures}$ learned preferences from well-aligned English models by implicit rewards and $\textit{transfers}$ them to other languages through iterative training. Specifically, we derive an implicit reward model from the logits of an English DPO-aligned model and its corresponding reference model. This reward model is then leveraged to annotate preference relations in cross-lingual instruction-following pairs, using English instructions to evaluate multilingual responses. The annotated data is subsequently used for multilingual DPO fine-tuning, facilitating preference knowledge transfer from English to other languages. Fine-tuning Llama3 for two iterations resulted in a 12.72% average improvement in Win Rate and a 5.97% increase in Length Control Win Rate across all training languages on the X-AlpacaEval leaderboard. Our findings demonstrate that leveraging existing English-aligned models can enable efficient and effective multilingual preference alignment, significantly reducing the need for extensive multilingual preference data. The code is available at https://github.com/ZNLP/Implicit-Cross-Lingual-Rewarding