 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Bias of SignGD and Adam on Multiclass Separable Data
Paper and Code
Feb 07, 2025
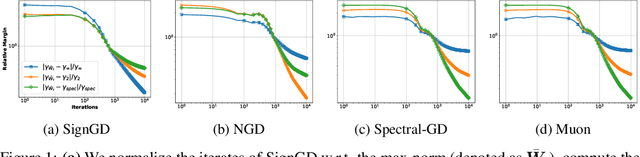
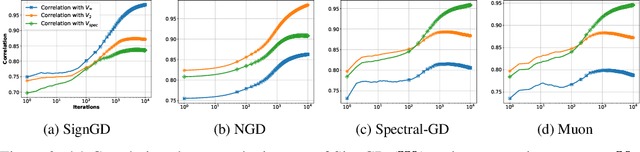
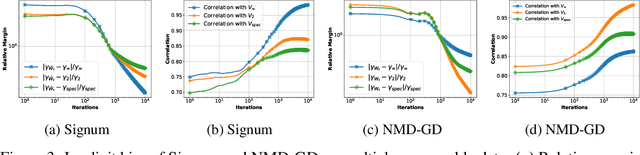
In the optimization of overparameterized models, different gradient-based methods can achieve zero training error yet converge to distinctly different solutions inducing different generalization properties. While a decade of research on implicit optimization bias has illuminated this phenomenon in various settings, even the foundational case of linear classification with separable data still has important open questions. We resolve a fundamental gap by characterizing the implicit bias of both Adam and Sign Gradient Descent in multi-class cross-entropy minimization: we prove that their iterates converge to solutions that maximize the margin with respect to the classifier matrix's max-norm and characterize the rate of convergence. We extend our results to general p-norm normalized steepest descent algorithms and to other multi-class losses.