 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplications of Topological Imbalance for Representation Learning on Biomedical Knowledge Graphs
Paper and Code
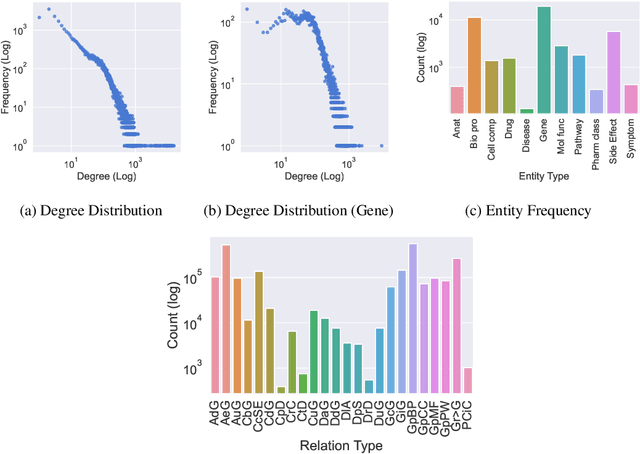
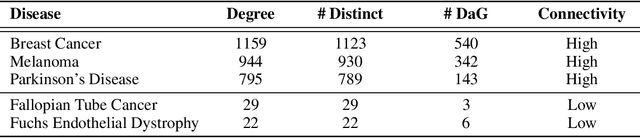
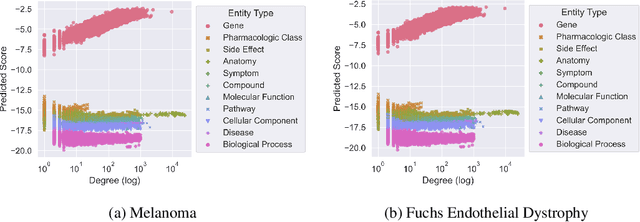
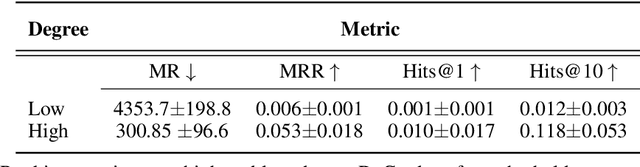
Improving on the standard of care for diseases is predicated on better treatments, which in turn relies on finding and developing new drugs. However, drug discovery is a complex and costly process. Adoption of methods from machine learning has given rise to creation of drug discovery knowledge graphs which utilize the inherent interconnected nature of the domain. Graph-based data modelling, combined with knowledge graph embeddings provide a more intuitive representation of the domain and are suitable for inference tasks such as predicting missing links. One such example would be producing ranked lists of likely associated genes for a given disease, often referred to as target discovery. It is thus critical that these predictions are not only pertinent but also biologically meaningful. However, knowledge graphs can be biased either directly due to the underlying data sources that are integrated or due to modeling choices in the construction of the graph, one consequence of which is that certain entities can get topologically overrepresented. We show how knowledge graph embedding models can be affected by this structural imbalance, resulting in densely connected entities being highly ranked no matter the context. We provide support for this observation across different datasets, models and predictive tasks. Further, we show how the graph topology can be perturbed to artificially alter the rank of a gene via random, biologically meaningless information. This suggests that such models can be more influenced by the frequency of entities rather than biological information encoded in the relations, creating issues when entity frequency is not a true reflection of underlying data. Our results highlight the importance of data modeling choices and emphasizes the need for practitioners to be mindful of these issues when interpreting model outputs and during knowledge graph composition.