 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMCI: Integrate Multi-view Contextual Information for Fact Extraction and Verification
Paper and Code


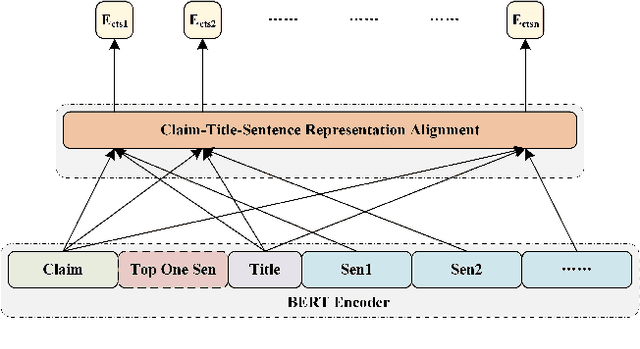

With the rapid development of automatic fake news detection technology, fact extraction and verification (FEVER) has been attracting more attention. The task aims to extract the most related fact evidences from millions of open-domain Wikipedia documents and then verify the credibility of corresponding claims. Although several strong models have been proposed for the task and they have made great progress, we argue that they fail to utilize multi-view contextual information and thus cannot obtain better performance. In this paper, we propose to integrate multi-view contextual information (IMCI) for fact extraction and verification. For each evidence sentence, we define two kinds of context, i.e. intra-document context and inter-document context}. Intra-document context consists of the document title and all the other sentences from the same document. Inter-document context consists of all other evidences which may come from different documents. Then we integrate the multi-view contextual information to encode the evidence sentences to handle the task. Our experimental results on FEVER 1.0 shared task show that our IMCI framework makes great progress on both fact extraction and verification, and achieves state-of-the-art performance with a winning FEVER score of 72.97% and label accuracy of 75.84% on the online blind test set. We also conduct ablation study to detect the impact of multi-view contextual information. Our codes will be released at https://github.com/phoenixsecularbird/IMCI.