 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI$^2$MD: 3D Action Representation Learning with Inter- and Intra-modal Mutual Distillation
Paper and Code
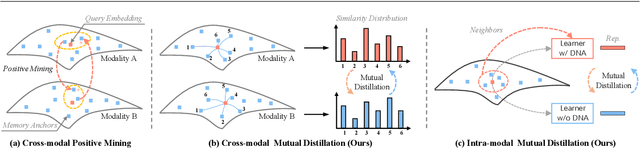
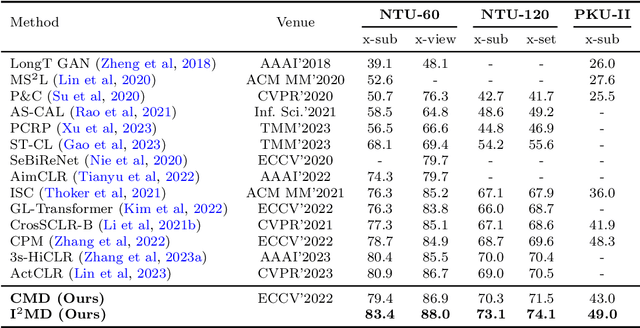
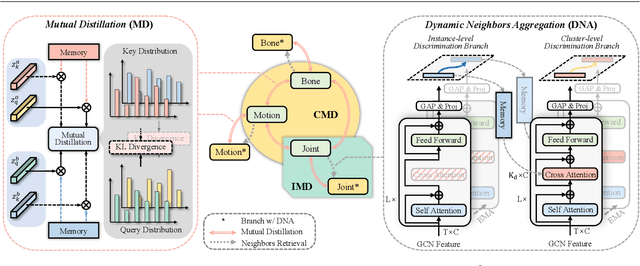
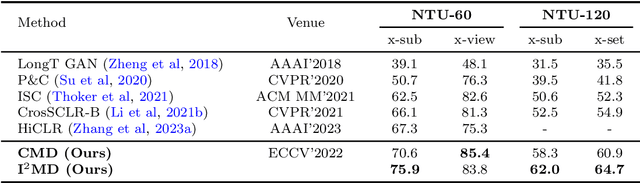
Recent progresses on self-supervised 3D human action representation learning are largely attributed to contrastive learning. However, in conventional contrastive frameworks, the rich complementarity between different skeleton modalities remains under-explored. Moreover, optimized with distinguishing self-augmented samples, models struggle with numerous similar positive instances in the case of limited action categories. In this work, we tackle the aforementioned problems by introducing a general Inter- and Intra-modal Mutual Distillation (I$^2$MD) framework. In I$^2$MD, we first re-formulate the cross-modal interaction as a Cross-modal Mutual Distillation (CMD) process. Different from existing distillation solutions that transfer the knowledge of a pre-trained and fixed teacher to the student, in CMD, the knowledge is continuously updated and bidirectionally distilled between modalities during pre-training. To alleviate the interference of similar samples and exploit their underlying contexts, we further design the Intra-modal Mutual Distillation (IMD) strategy, In IMD, the Dynamic Neighbors Aggregation (DNA) mechanism is first introduced, where an additional cluster-level discrimination branch is instantiated in each modality. It adaptively aggregates highly-correlated neighboring features, forming local cluster-level contrasting. Mutual distillation is then performed between the two branches for cross-level knowledge exchange. Extensive experiments on three datasets show that our approach sets a series of new records.