 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Convolution Networks for Biomedical Image Segmentation
Paper and Code

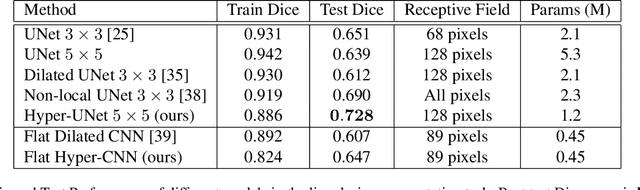


The convolution operation is a central building block of neural network architectures widely used in computer vision. The size of the convolution kernels determines both the expressiveness of convolutional neural networks (CNN), as well as the number of learnable parameters. Increasing the network capacity to capture rich pixel relationships requires increasing the number of learnable parameters, often leading to overfitting and/or lack of robustness. In this paper, we propose a powerful novel building block, the hyper-convolution, which implicitly represents the convolution kernel as a function of kernel coordinates. Hyper-convolutions enable decoupling the kernel size, and hence its receptive field, from the number of learnable parameters. In our experiments, focused on challenging biomedical image segmentation tasks, we demonstrate that replacing regular convolutions with hyper-convolutions leads to more efficient architectures that achieve improved accuracy. Our analysis also shows that learned hyper-convolutions are naturally regularized, which can offer better generalization performance. We believe that hyper-convolutions can be a powerful building block in future neural network architectures solving computer vision tasks.