 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid scene Compression for Visual Localization
Paper and Code
Jul 19, 2018

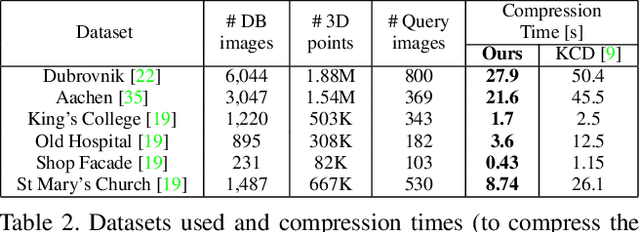

Localizing an image wrt. a large scale 3D scene represents a core task for many computer vision applications. The increasing size of available 3D scenes makes visual localization prohibitively slow for real-time applications due to the large amount of data that the system needs to analyze and store. Therefore, compression becomes a necessary step in order to manage large scenes. In this work, we introduce a new hybrid compression algorithm that selects two subsets of points from the original 3D model: a small set of points with full appearance information, and an additional, larger set of points with compressed information. Our algorithm takes into account both spatial coverage as well as appearance uniqueness during compression. Quantization techniques are exploited during compression time, reducing run-time wrt. previous compression methods. A RANSAC variant tailored to our specific compression output is also introduced. Experiments on six large-scale datasets show that our method performs better than previous compression techniques in terms of memory, run-time and accuracy. Furthermore, the localization rates and pose accuracy obtained are comparable to state-of-the-art feature-based methods, while using a small fraction of the memory.