 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Local-Global Transformer for Image Dehazing
Paper and Code



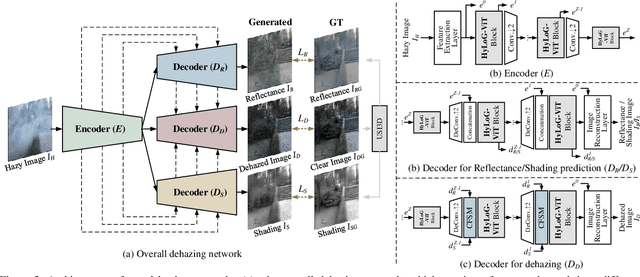
Recently, the Vision Transformer (ViT) has shown impressive performance on high-level and low-level vision tasks. In this paper, we propose a new ViT architecture, named Hybrid Local-Global Vision Transformer (HyLoG-ViT), for single image dehazing. The HyLoG-ViT block consists of two paths, the local ViT path and the global ViT path, which are used to capture local and global dependencies. The hybrid features are fused via convolution layers. As a result, the HyLoG-ViT reduces the computational complexity and introduces locality in the networks. Then, the HyLoG-ViT blocks are incorporated within our dehazing networks, which jointly learn the intrinsic image decomposition and image dehazing. Specifically, the network consists of one shared encoder and three decoders for reflectance prediction, shading prediction, and haze-free image generation. The tasks of reflectance and shading prediction can produce meaningful intermediate features that can serve as complementary features for haze-free image generation. To effectively aggregate the complementary features, we propose a complementary features selection module (CFSM) to select the useful ones for image dehazing. Extensive experiments on homogeneous, non-homogeneous, and nighttime dehazing tasks reveal that our proposed Transformer-based dehazing network can achieve comparable or even better performance than CNNs-based dehazing models.