 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection
Paper and Code
Apr 02, 2021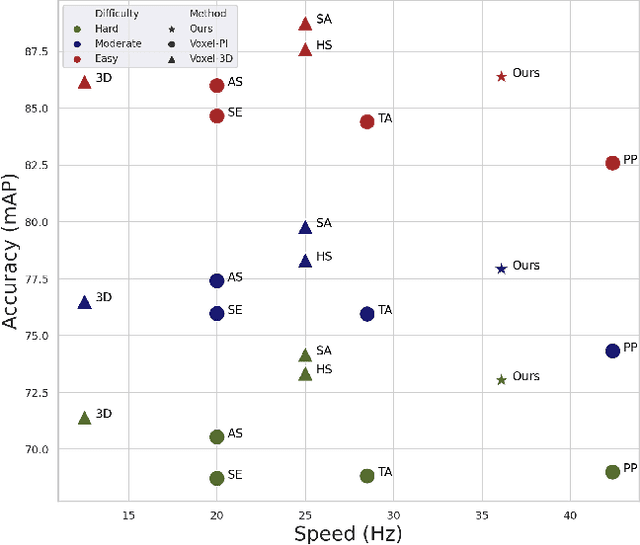
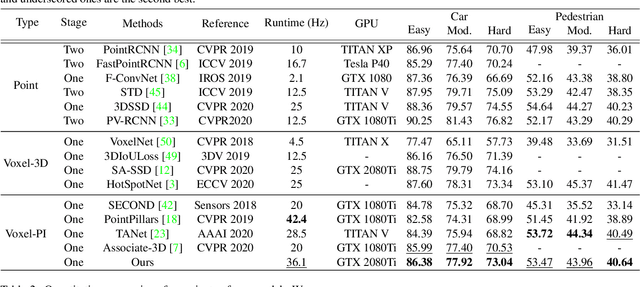
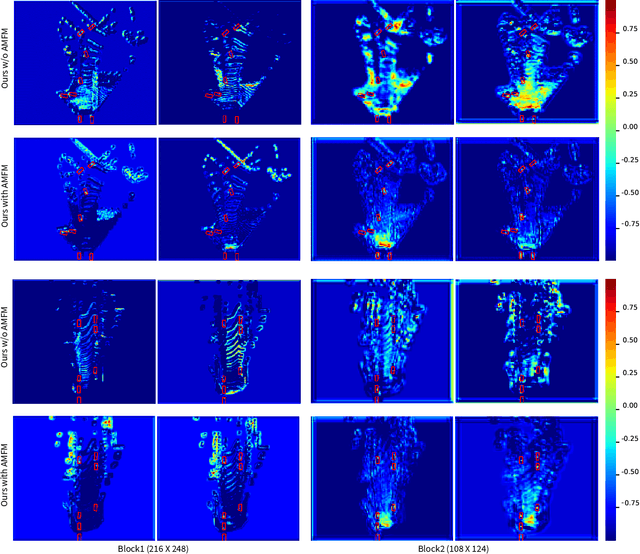
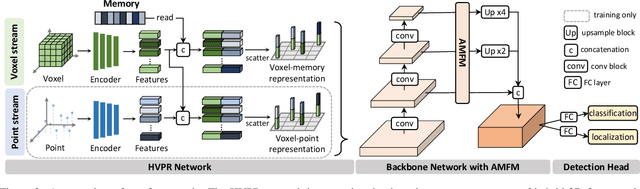
We address the problem of 3D object detection, that is, estimating 3D object bounding boxes from point clouds. 3D object detection methods exploit either voxel-based or point-based features to represent 3D objects in a scene. Voxel-based features are efficient to extract, while they fail to preserve fine-grained 3D structures of objects. Point-based features, on the other hand, represent the 3D structures more accurately, but extracting these features is computationally expensive. We introduce in this paper a novel single-stage 3D detection method having the merit of both voxel-based and point-based features. To this end, we propose a new convolutional neural network (CNN) architecture, dubbed HVPR, that integrates both features into a single 3D representation effectively and efficiently. Specifically, we augment the point-based features with a memory module to reduce the computational cost. We then aggregate the features in the memory, semantically similar to each voxel-based one, to obtain a hybrid 3D representation in a form of a pseudo image, allowing to localize 3D objects in a single stage efficiently. We also propose an Attentive Multi-scale Feature Module (AMFM) that extracts scale-aware features considering the sparse and irregular patterns of point clouds. Experimental results on the KITTI dataset demonstrate the effectiveness and efficiency of our approach, achieving a better compromise in terms of speed and accuracy.