 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow To Avoid Being Eaten By a Grue: Exploration Strategies for Text-Adventure Agents
Paper and Code


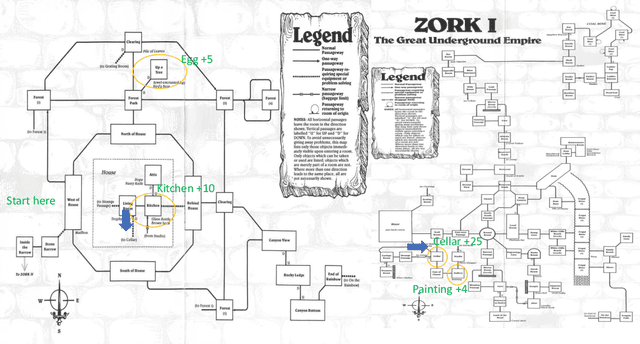
Text-based games -- in which an agent interacts with the world through textual natural language -- present us with the problem of combinatorially-sized action-spaces. Most current reinforcement learning algorithms are not capable of effectively handling such a large number of possible actions per turn. Poor sample efficiency, consequently, results in agents that are unable to pass bottleneck states, where they are unable to proceed because they do not see the right action sequence to pass the bottleneck enough times to be sufficiently reinforced. Building on prior work using knowledge graphs in reinforcement learning, we introduce two new game state exploration strategies. We compare our exploration strategies against strong baselines on the classic text-adventure game, Zork1, where prior agent have been unable to get past a bottleneck where the agent is eaten by a Grue.