Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Robust are Limit Order Book Representations under Data Perturbation?
Paper and Code
Oct 10, 2021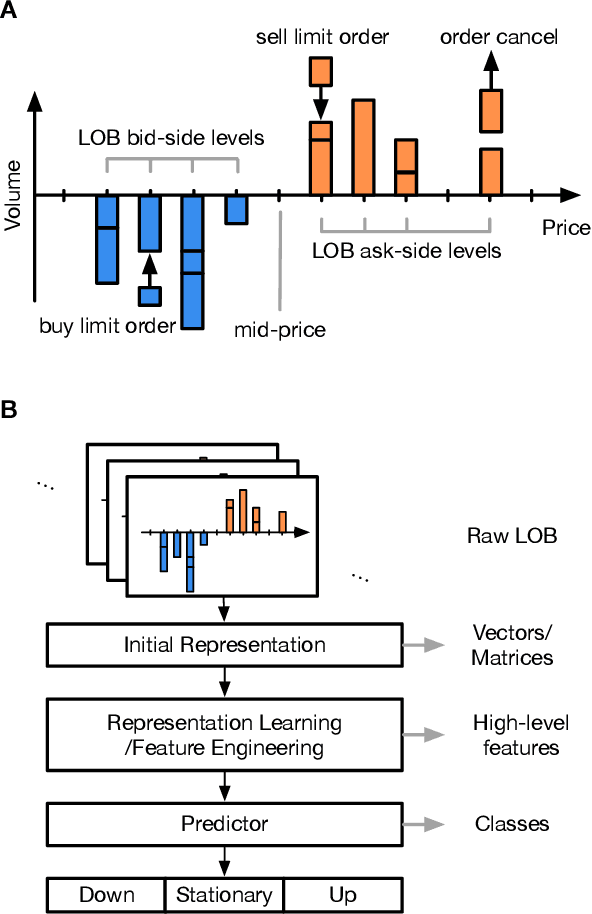
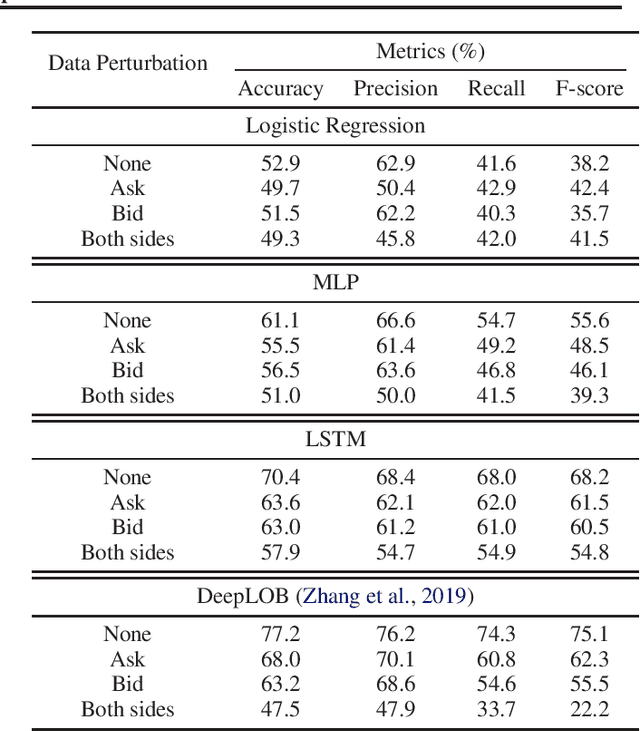
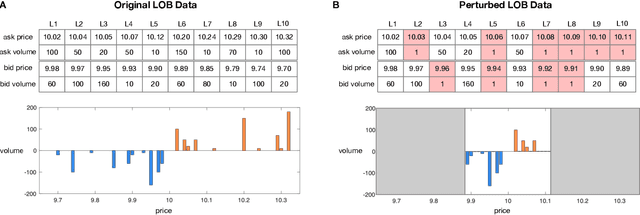
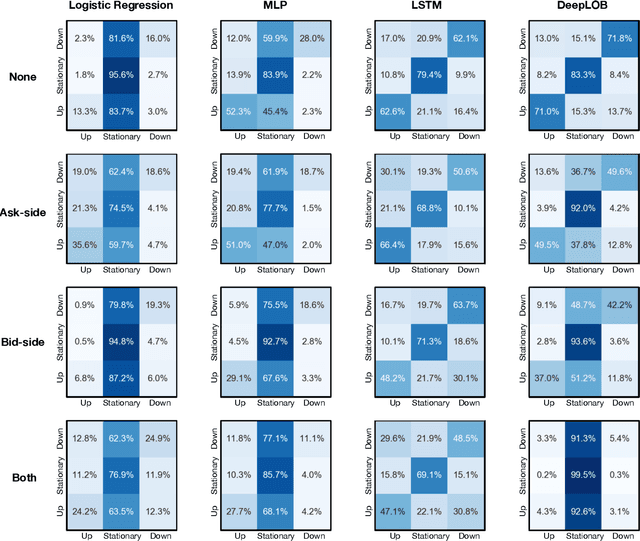
The success of machine learning models in the financial domain is highly reliant on the quality of the data representation. In this paper, we focus on the representation of limit order book data and discuss the opportunities and challenges for learning representations of such data. We also experimentally analyse the issues associated with existing representations and present a guideline for future research in this area.
View paper on