 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Predictable Are Large Language Model Capabilities? A Case Study on BIG-bench
Paper and Code
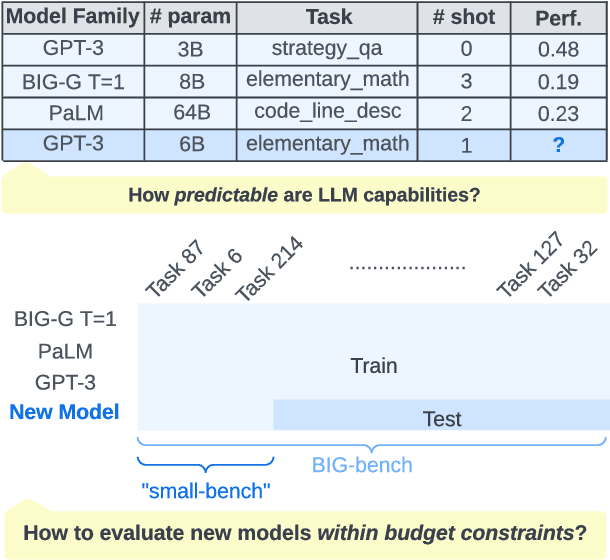
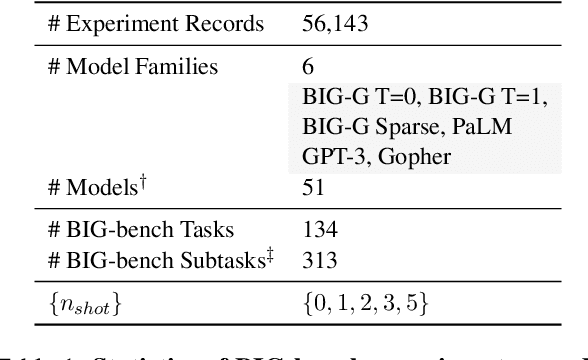
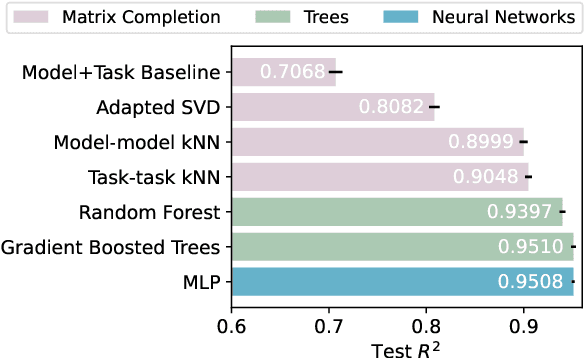

We investigate the predictability of large language model (LLM) capabilities: given records of past experiments using different model families, numbers of parameters, tasks, and numbers of in-context examples, can we accurately predict LLM performance on new experiment configurations? Answering this question has practical implications for LLM users (e.g., deciding which models to try), developers (e.g., prioritizing evaluation on representative tasks), and the research community (e.g., identifying hard-to-predict capabilities that warrant further investigation). We study the performance prediction problem on experiment records from BIG-bench. On a random train-test split, an MLP-based predictor achieves RMSE below 5%, demonstrating the presence of learnable patterns within the experiment records. Further, we formulate the problem of searching for "small-bench," an informative subset of BIG-bench tasks from which the performance of the full set can be maximally recovered, and find a subset as informative for evaluating new model families as BIG-bench Hard, while being 3x smaller.