 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow is Visual Attention Influenced by Text Guidance? Database and Model
Paper and Code

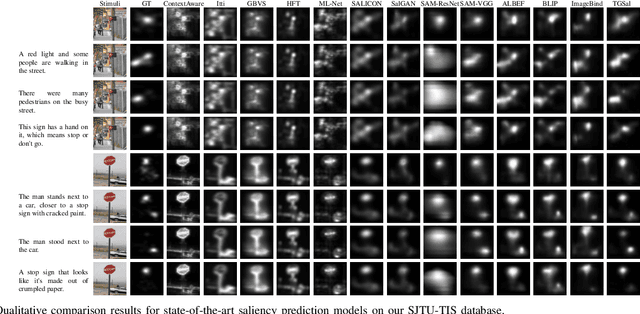
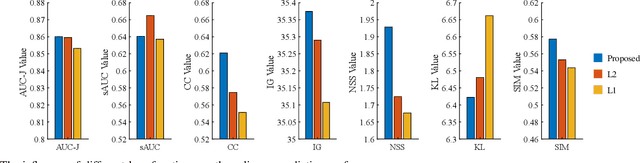
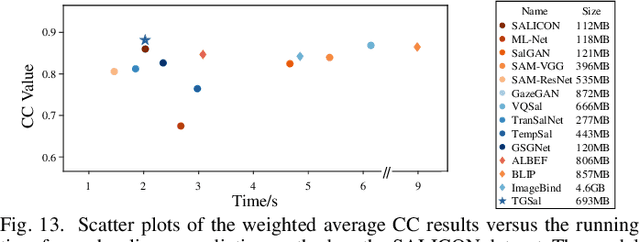
The analysis and prediction of visual attention have long been crucial tasks in the fields of computer vision and image processing. In practical applications, images are generally accompanied by various text descriptions, however, few studies have explored the influence of text descriptions on visual attention, let alone developed visual saliency prediction models considering text guidance. In this paper, we conduct a comprehensive study on text-guided image saliency (TIS) from both subjective and objective perspectives. Specifically, we construct a TIS database named SJTU-TIS, which includes 1200 text-image pairs and the corresponding collected eye-tracking data. Based on the established SJTU-TIS database, we analyze the influence of various text descriptions on visual attention. Then, to facilitate the development of saliency prediction models considering text influence, we construct a benchmark for the established SJTU-TIS database using state-of-the-art saliency models. Finally, considering the effect of text descriptions on visual attention, while most existing saliency models ignore this impact, we further propose a text-guided saliency (TGSal) prediction model, which extracts and integrates both image features and text features to predict the image saliency under various text-description conditions. Our proposed model significantly outperforms the state-of-the-art saliency models on both the SJTU-TIS database and the pure image saliency databases in terms of various evaluation metrics. The SJTU-TIS database and the code of the proposed TGSal model will be released at: https://github.com/IntMeGroup/TGSal.