Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow good is PAC-Bayes at explaining generalisation?
Paper and Code
Mar 11, 2025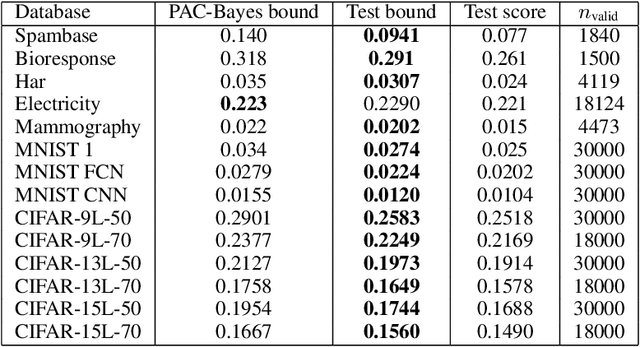
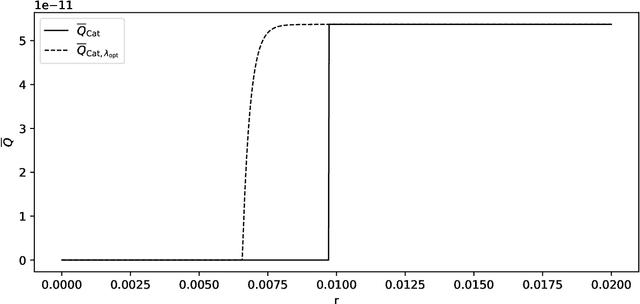
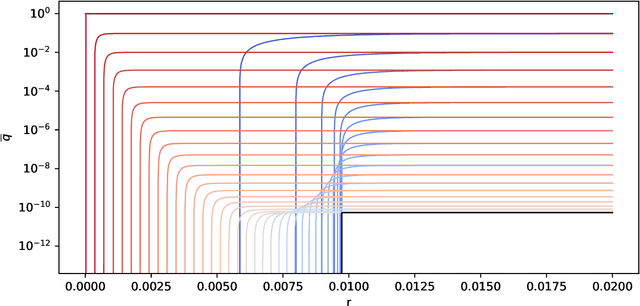
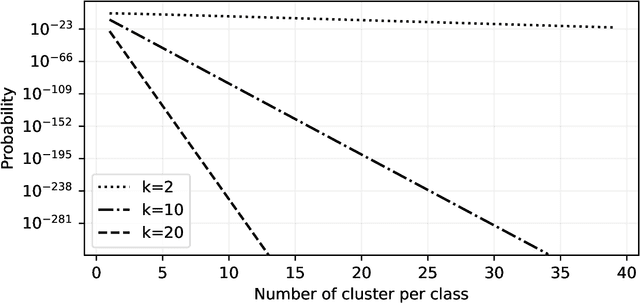
We discuss necessary conditions for a PAC-Bayes bound to provide a meaningful generalisation guarantee. Our analysis reveals that the optimal generalisation guarantee depends solely on the distribution of the risk induced by the prior distribution. In particular, achieving a target generalisation level is only achievable if the prior places sufficient mass on high-performing predictors. We relate these requirements to the prevalent practice of using data-dependent priors in deep learning PAC-Bayes applications, and discuss the implications for the claim that PAC-Bayes ``explains'' generalisation.
View paper on