 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizontal-to-Vertical Video Conversion
Paper and Code
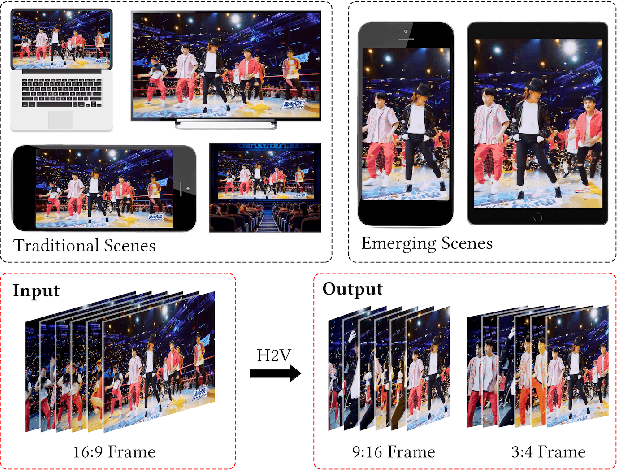
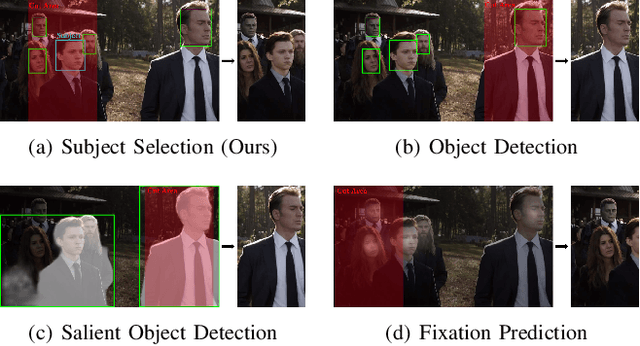
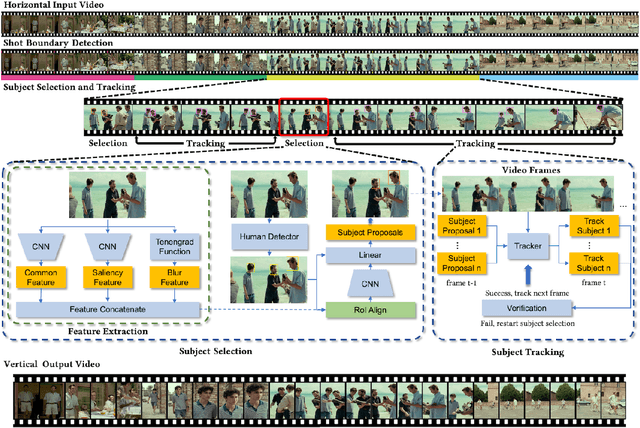
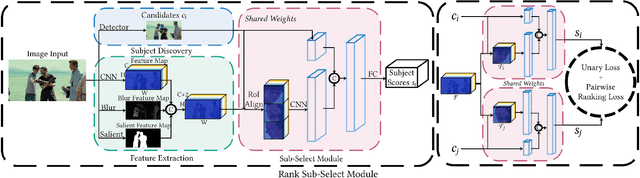
Alongside the prevalence of mobile videos, the general public leans towards consuming vertical videos on hand-held devices. To revitalize the exposure of horizontal contents, we hereby set forth the exploration of automated horizontal-to-vertical (abbreviated as H2V) video conversion with our proposed H2V framework, accompanied by an accurately annotated H2V-142K dataset. Concretely, H2V framework integrates video shot boundary detection, subject selection and multi-object tracking to facilitate the subject-preserving conversion, wherein the key is subject selection. To achieve so, we propose a Rank-SS module that detects human objects, then selects the subject-to-preserve via exploiting location, appearance, and salient cues. Afterward, the framework automatically crops the video around the subject to produce vertical contents from horizontal sources. To build and evaluate our H2V framework, H2V-142K dataset is densely annotated with subject bounding boxes for 125 videos with 132K frames and 9,500 video covers, upon which we demonstrate superior subject selection performance comparing to traditional salient approaches, and exhibit promising horizontal-to-vertical conversion performance overall. By publicizing this dataset as well as our approach, we wish to pave the way for more valuable endeavors on the horizontal-to-vertical video conversion task.