 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-throughput relation extraction algorithm development associating knowledge articles and electronic health records
Paper and Code
Sep 08, 2020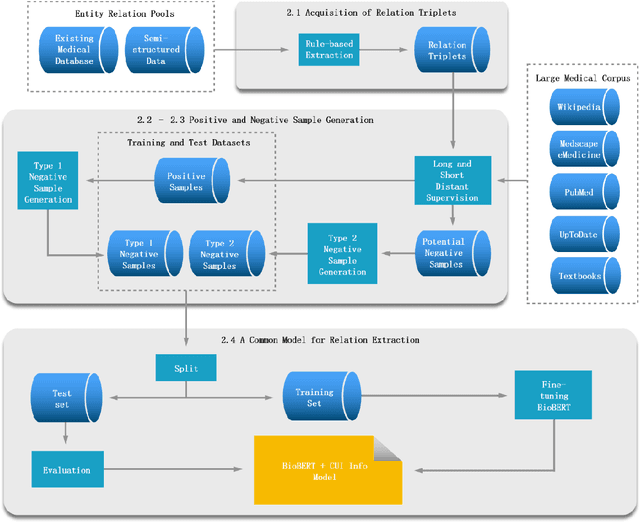
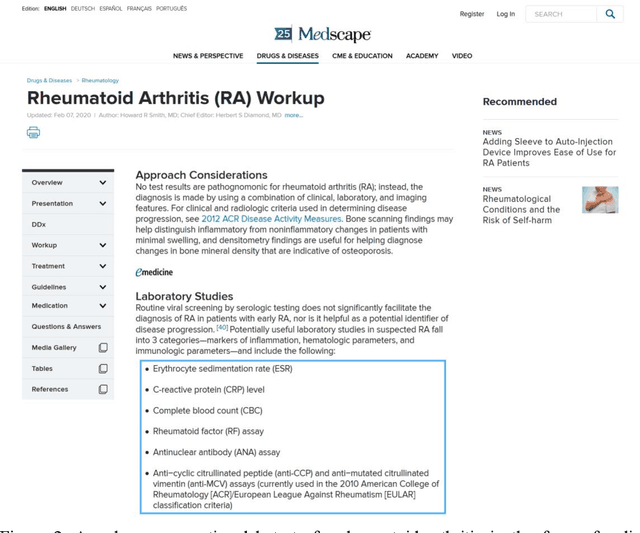
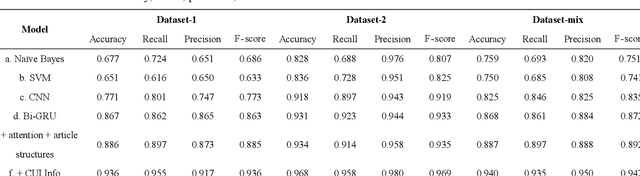
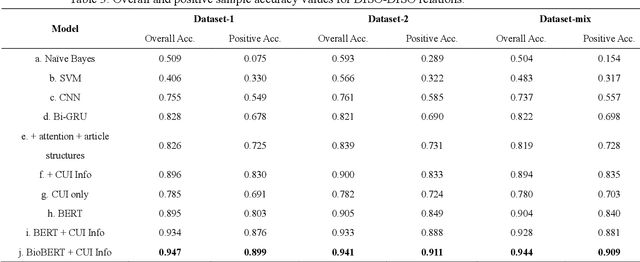
Objective: Medical relations are the core components of medical knowledge graphs that are needed for healthcare artificial intelligence. However, the requirement of expert annotation by conventional algorithm development processes creates a major bottleneck for mining new relations. In this paper, we present Hi-RES, a framework for high-throughput relation extraction algorithm development. We also show that combining knowledge articles with electronic health records (EHRs) significantly increases the classification accuracy. Methods: We use relation triplets obtained from structured databases and semistructured webpages to label sentences from target corpora as positive training samples. Two methods are also provided for creating improved negative samples by combining positive samples with na\"ive negative samples. We propose a common model that summarizes sentence information using large-scale pretrained language models and multi-instance attention, which then joins with the concept embeddings trained from the EHRs for relation prediction. Results: We apply the Hi-RES framework to develop classification algorithms for disorder-disorder relations and disorder-location relations. Millions of sentences are created as training data. Using pretrained language models and EHR-based embeddings individually provides considerable accuracy increases over those of previous models. Joining them together further tremendously increases the accuracy to 0.947 and 0.998 for the two sets of relations, respectively, which are 10-17 percentage points higher than those of previous models. Conclusion: Hi-RES is an efficient framework for achieving high-throughput and accurate relation extraction algorithm development.