 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Speed and High-Quality Text-to-Lip Generation
Paper and Code
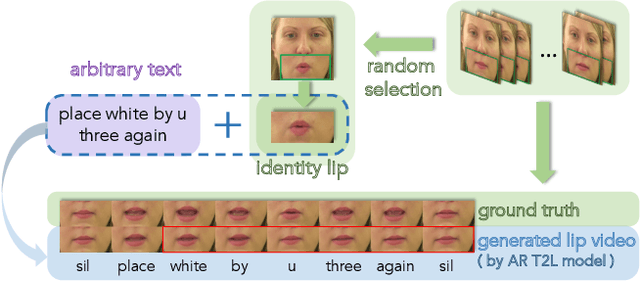


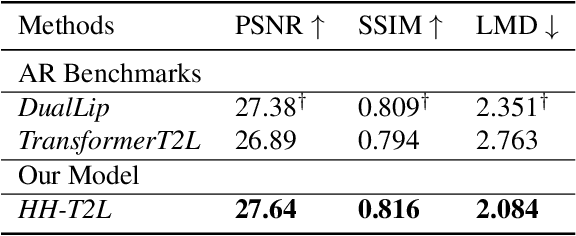
As a key component of talking face generation, lip movements generation determines the naturalness and coherence of the generated talking face video. Prior literature mainly focuses on speech-to-lip generation while there is a paucity in text-to-lip (T2L) generation. T2L is a challenging task and existing end-to-end works depend on the attention mechanism and autoregressive (AR) decoding manner. However, the AR decoding manner generates current lip frame conditioned on frames generated previously, which inherently hinders the inference speed, and also has a detrimental effect on the quality of generated lip frames due to error propagation. This encourages the research of parallel T2L generation. In this work, we propose a novel parallel decoding model for high-speed and high-quality text-to-lip generation (HH-T2L). Specifically, we predict the duration of the encoded linguistic features and model the target lip frames conditioned on the encoded linguistic features with their duration in a non-autoregressive manner. Furthermore, we incorporate the structural similarity index loss and adversarial learning to improve perceptual quality of generated lip frames and alleviate the blurry prediction problem. Extensive experiments conducted on GRID and TCD-TIMIT datasets show that 1) HH-T2L generates lip movements with competitive quality compared with the state-of-the-art AR T2L model DualLip and exceeds the baseline AR model TransformerT2L by a notable margin benefiting from the mitigation of the error propagation problem; and 2) exhibits distinct superiority in inference speed (an average speedup of 19$\times$ than DualLip on TCD-TIMIT).