 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Image Inpainting with GAN Inversion
Paper and Code
Aug 25, 2022
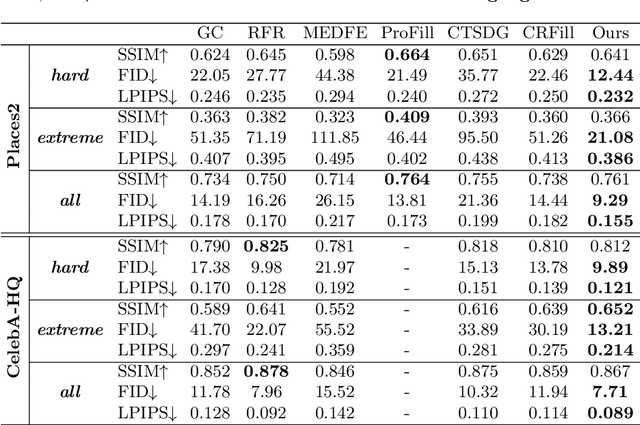
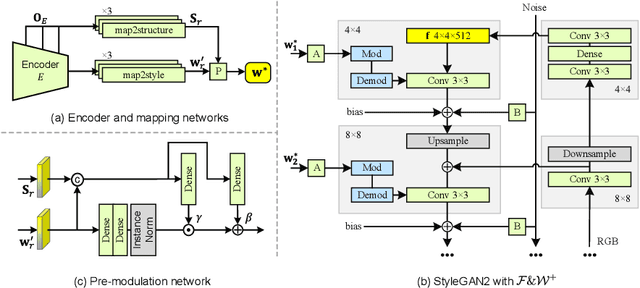
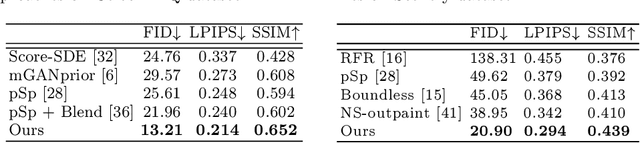
Image inpainting seeks a semantically consistent way to recover the corrupted image in the light of its unmasked content. Previous approaches usually reuse the well-trained GAN as effective prior to generate realistic patches for missing holes with GAN inversion. Nevertheless, the ignorance of a hard constraint in these algorithms may yield the gap between GAN inversion and image inpainting. Addressing this problem, in this paper, we devise a novel GAN inversion model for image inpainting, dubbed InvertFill, mainly consisting of an encoder with a pre-modulation module and a GAN generator with F&W+ latent space. Within the encoder, the pre-modulation network leverages multi-scale structures to encode more discriminative semantics into style vectors. In order to bridge the gap between GAN inversion and image inpainting, F&W+ latent space is proposed to eliminate glaring color discrepancy and semantic inconsistency. To reconstruct faithful and photorealistic images, a simple yet effective Soft-update Mean Latent module is designed to capture more diverse in-domain patterns that synthesize high-fidelity textures for large corruptions. Comprehensive experiments on four challenging datasets, including Places2, CelebA-HQ, MetFaces, and Scenery, demonstrate that our InvertFill outperforms the advanced approaches qualitatively and quantitatively and supports the completion of out-of-domain images well.