 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHedging using reinforcement learning: Contextual $k$-Armed Bandit versus $Q$-learning
Paper and Code
Jul 03, 2020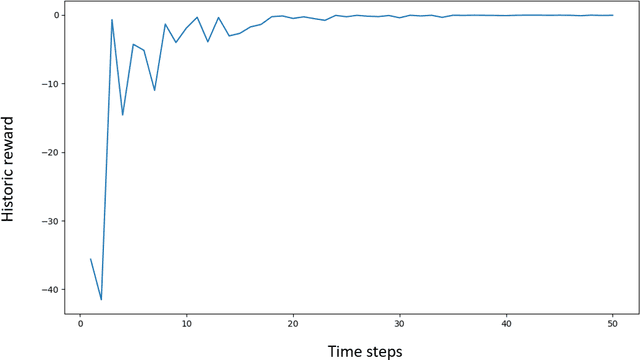
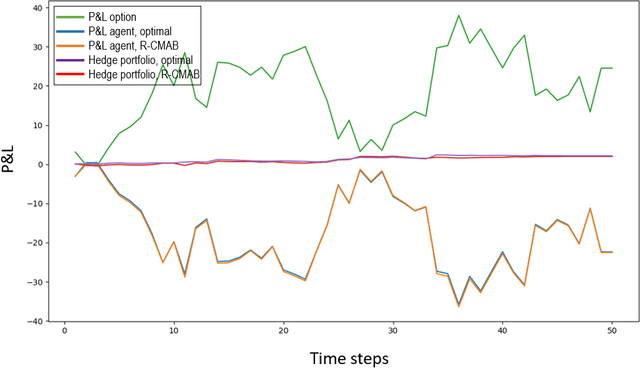
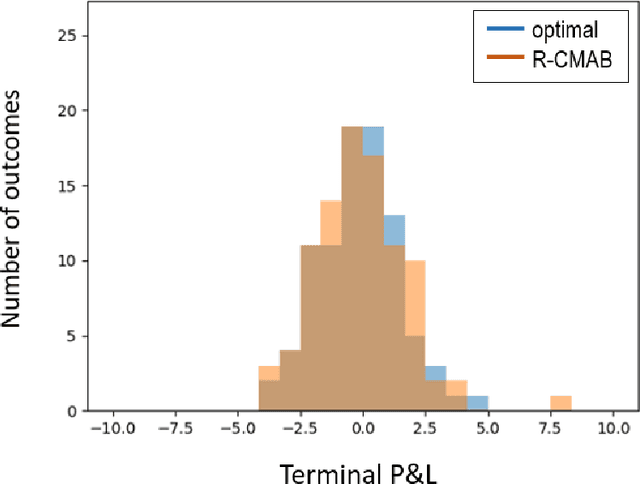
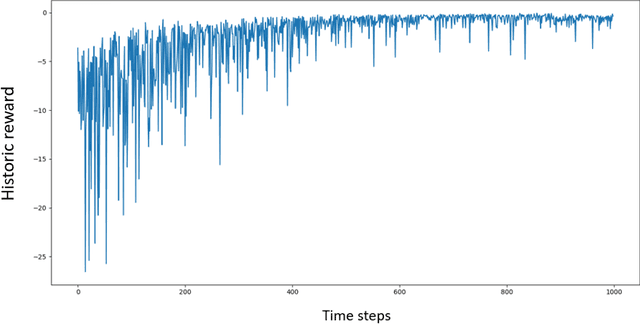
The construction of replication strategies for contingent claims in the presence of risk and market friction is a key problem of financial engineering. In real markets, continuous replication, such as in the model of Black, Scholes and Merton, is not only unrealistic but it is also undesirable due to high transaction costs. Over the last decades stochastic optimal-control methods have been developed to balance between effective replication and losses. More recently, with the rise of artificial intelligence, temporal-difference Reinforcement Learning, in particular variations of $Q$-learning in conjunction with Deep Neural Networks, have attracted significant interest. From a practical point of view, however, such methods are often relatively sample inefficient, hard to train and lack performance guarantees. This motivates the investigation of a stable benchmark algorithm for hedging. In this article, the hedging problem is viewed as an instance of a risk-averse contextual $k$-armed bandit problem, for which a large body of theoretical results and well-studied algorithms are available. We find that the $k$-armed bandit model naturally fits to the $P\&L$ formulation of hedging, providing for a more accurate and sample efficient approach than $Q$-learning and reducing to the Black-Scholes model in the absence of transaction costs and risks.