 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeavy-Tailed Analogues of the Covariance Matrix for ICA
Paper and Code
Feb 22, 2017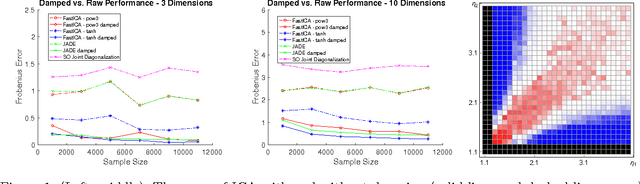
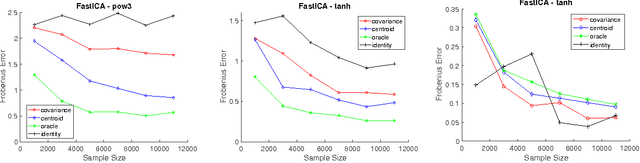
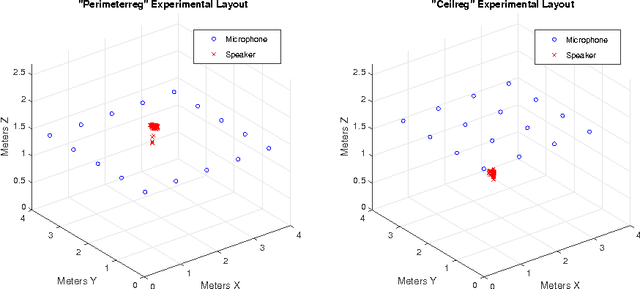
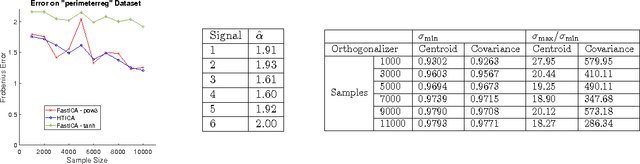
Independent Component Analysis (ICA) is the problem of learning a square matrix $A$, given samples of $X=AS$, where $S$ is a random vector with independent coordinates. Most existing algorithms are provably efficient only when each $S_i$ has finite and moderately valued fourth moment. However, there are practical applications where this assumption need not be true, such as speech and finance. Algorithms have been proposed for heavy-tailed ICA, but they are not practical, using random walks and the full power of the ellipsoid algorithm multiple times. The main contributions of this paper are: (1) A practical algorithm for heavy-tailed ICA that we call HTICA. We provide theoretical guarantees and show that it outperforms other algorithms in some heavy-tailed regimes, both on real and synthetic data. Like the current state-of-the-art, the new algorithm is based on the centroid body (a first moment analogue of the covariance matrix). Unlike the state-of-the-art, our algorithm is practically efficient. To achieve this, we use explicit analytic representations of the centroid body, which bypasses the use of the ellipsoid method and random walks. (2) We study how heavy tails affect different ICA algorithms, including HTICA. Somewhat surprisingly, we show that some algorithms that use the covariance matrix or higher moments can successfully solve a range of ICA instances with infinite second moment. We study this theoretically and experimentally, with both synthetic and real-world heavy-tailed data.