 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeavy-Tail Phenomenon in Decentralized SGD
Paper and Code
May 16, 2022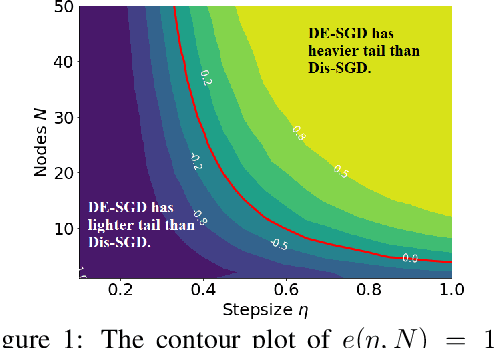
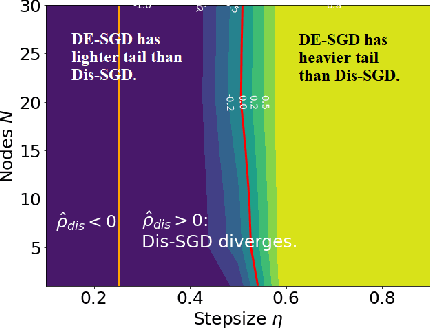
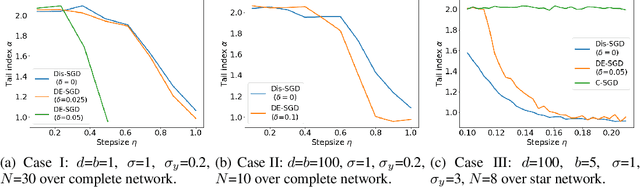
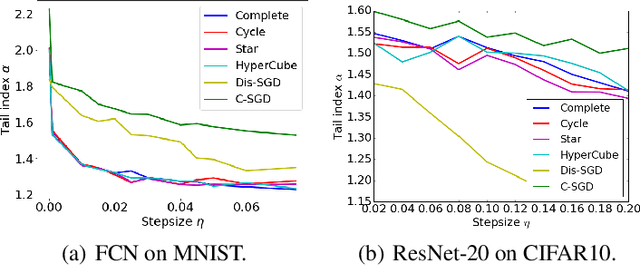
Recent theoretical studies have shown that heavy-tails can emerge in stochastic optimization due to `multiplicative noise', even under surprisingly simple settings, such as linear regression with Gaussian data. While these studies have uncovered several interesting phenomena, they consider conventional stochastic optimization problems, which exclude decentralized settings that naturally arise in modern machine learning applications. In this paper, we study the emergence of heavy-tails in decentralized stochastic gradient descent (DE-SGD), and investigate the effect of decentralization on the tail behavior. We first show that, when the loss function at each computational node is twice continuously differentiable and strongly convex outside a compact region, the law of the DE-SGD iterates converges to a distribution with polynomially decaying (heavy) tails. To have a more explicit control on the tail exponent, we then consider the case where the loss at each node is a quadratic, and show that the tail-index can be estimated as a function of the step-size, batch-size, and the topological properties of the network of the computational nodes. Then, we provide theoretical and empirical results showing that DE-SGD has heavier tails than centralized SGD. We also compare DE-SGD to disconnected SGD where nodes distribute the data but do not communicate. Our theory uncovers an interesting interplay between the tails and the network structure: we identify two regimes of parameters (stepsize and network size), where DE-SGD can have lighter or heavier tails than disconnected SGD depending on the regime. Finally, to support our theoretical results, we provide numerical experiments conducted on both synthetic data and neural networks.