 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten Text Segmentation via End-to-End Learning of Convolutional Neural Network
Paper and Code
Jun 12, 2019
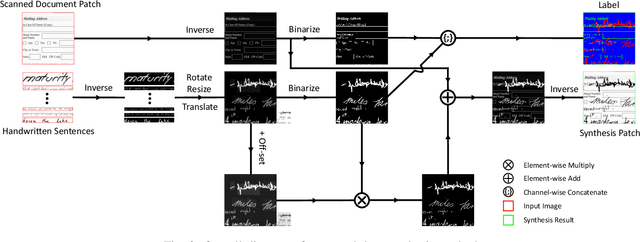

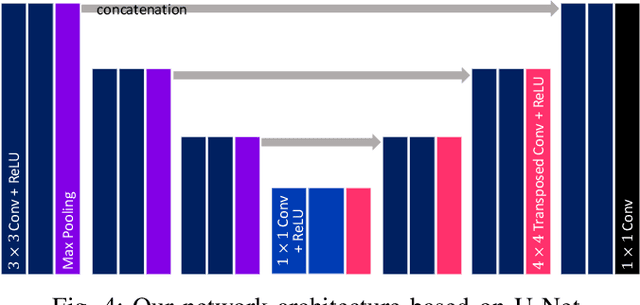
We present a new handwritten text segmentation method by training a convolutional neural network (CNN) in an end-to-end manner. Many conventional methods addressed this problem by extracting connected components and then classifying them. However, this two-step approach has limitations when handwritten components and machine-printed parts are overlapping. Unlike conventional methods, we develop an end-to-end deep CNN for this problem, which does not need any preprocessing steps. Since there is no publicly available dataset for this goal and pixel-wise annotations are time-consuming and costly, we also propose a data synthesis algorithm that generates realistic training samples. For training our network, we develop a cross-entropy based loss function that addresses the imbalance problems. Experimental results on synthetic and real images show the effectiveness of the proposed method. Specifically, the proposed network has been trained solely on synthetic images, nevertheless the removal of handwritten text in real documents improves OCR performance from 71.13% to 92.50%, showing the generalization performance of our network and synthesized images.