 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinated Adversarial Control for Conservative Offline Policy Evaluation
Paper and Code
Mar 02, 2023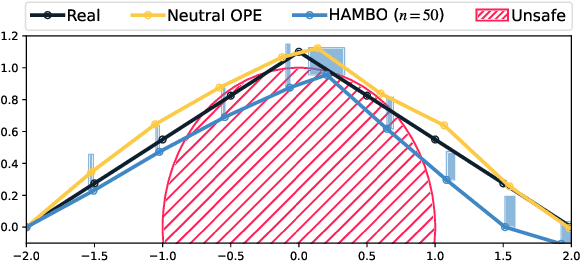
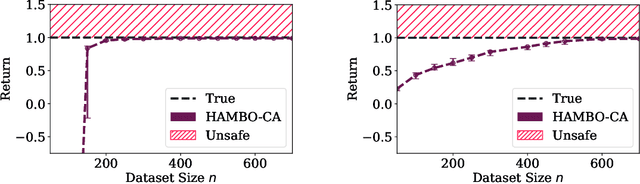
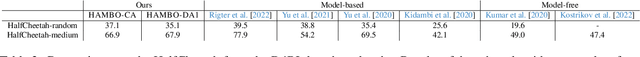
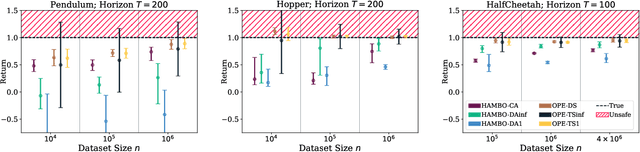
We study the problem of conservative off-policy evaluation (COPE) where given an offline dataset of environment interactions, collected by other agents, we seek to obtain a (tight) lower bound on a policy's performance. This is crucial when deciding whether a given policy satisfies certain minimal performance/safety criteria before it can be deployed in the real world. To this end, we introduce HAMBO, which builds on an uncertainty-aware learned model of the transition dynamics. To form a conservative estimate of the policy's performance, HAMBO hallucinates worst-case trajectories that the policy may take, within the margin of the models' epistemic confidence regions. We prove that the resulting COPE estimates are valid lower bounds, and, under regularity conditions, show their convergence to the true expected return. Finally, we discuss scalable variants of our approach based on Bayesian Neural Networks and empirically demonstrate that they yield reliable and tight lower bounds in various continuous control environments.