 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVT2RPM: An Empirical Study for General Video Transformer Adaptation to Remote Physiological Measurement
Paper and Code


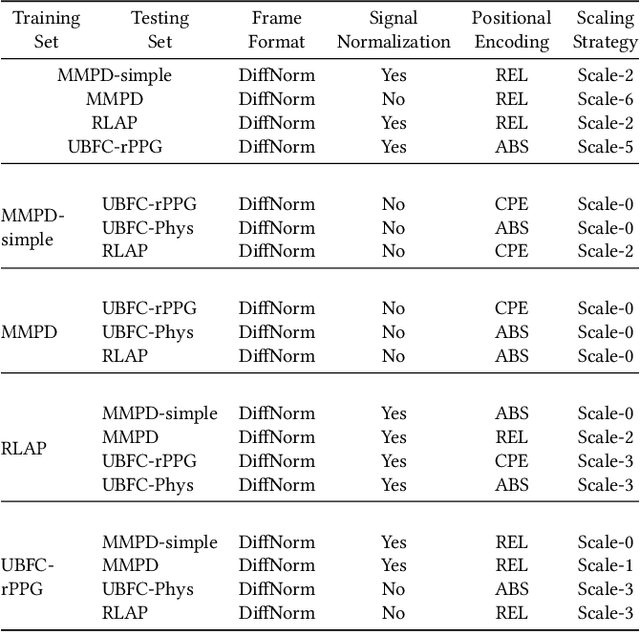

Remote physiological measurement (RPM) is an essential tool for healthcare monitoring as it enables the measurement of physiological signs, e.g., heart rate, in a remote setting via physical wearables. Recently, with facial videos, we have seen rapid advancements in video-based RPMs. However, adopting facial videos for RPM in the clinical setting largely depends on the accuracy and robustness (work across patient populations). Fortunately, the capability of the state-of-the-art transformer architecture in general (natural) video understanding has resulted in marked improvements and has been translated to facial understanding, including RPM. However, existing RPM methods usually need RPM-specific modules, e.g., temporal difference convolution and handcrafted feature maps. Although these customized modules can increase accuracy, they are not demonstrated for their robustness across datasets. Further, due to their customization of the transformer architecture, they cannot use the advancements made in general video transformers (GVT). In this study, we interrogate the GVT architecture and empirically analyze how the training designs, i.e., data pre-processing and network configurations, affect the model performance applied to RPM. Based on the structure of video transformers, we propose to configure its spatiotemporal hierarchy to align with the dense temporal information needed in RPM for signal feature extraction. We define several practical guidelines and gradually adapt GVTs for RPM without introducing RPM-specific modules. Our experiments demonstrate favorable results to existing RPM-specific module counterparts. We conducted extensive experiments with five datasets using intra-dataset and cross-dataset settings. We highlight that the proposed guidelines GVT2RPM can be generalized to any video transformers and is robust to various datasets.