 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
Paper and Code


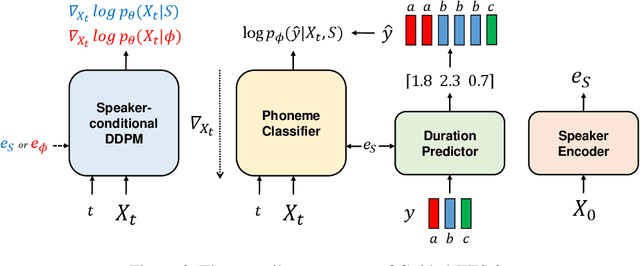

We propose Guided-TTS 2, a diffusion-based generative model for high-quality adaptive TTS using untranscribed data. Guided-TTS 2 combines a speaker-conditional diffusion model with a speaker-dependent phoneme classifier for adaptive text-to-speech. We train the speaker-conditional diffusion model on large-scale untranscribed datasets for a classifier-free guidance method and further fine-tune the diffusion model on the reference speech of the target speaker for adaptation, which only takes 40 seconds. We demonstrate that Guided-TTS 2 shows comparable performance to high-quality single-speaker TTS baselines in terms of speech quality and speaker similarity with only a ten-second untranscribed data. We further show that Guided-TTS 2 outperforms adaptive TTS baselines on multi-speaker datasets even with a zero-shot adaptation setting. Guided-TTS 2 can adapt to a wide range of voices only using untranscribed speech, which enables adaptive TTS with the voice of non-human characters such as Gollum in \textit{"The Lord of the Rings"}.