 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Policy Exploration for Markov Decision Processes using an Uncertainty-Based Value-of-Information Criterion
Paper and Code
Feb 05, 2018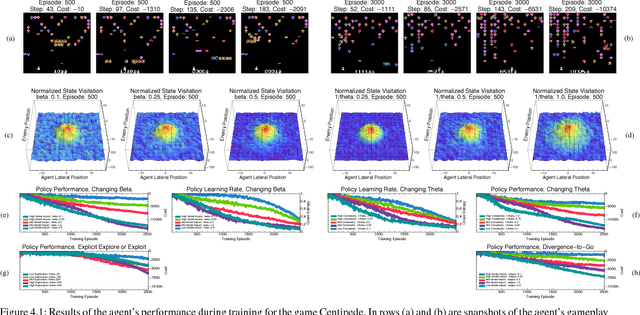
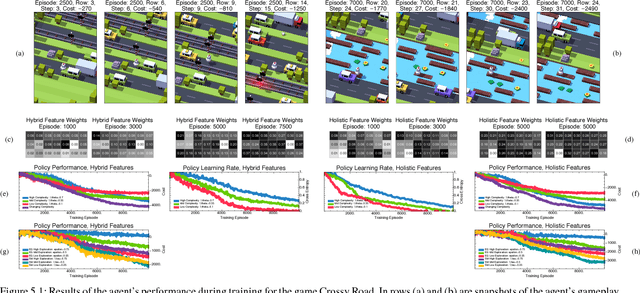
Reinforcement learning in environments with many action-state pairs is challenging. At issue is the number of episodes needed to thoroughly search the policy space. Most conventional heuristics address this search problem in a stochastic manner. This can leave large portions of the policy space unvisited during the early training stages. In this paper, we propose an uncertainty-based, information-theoretic approach for performing guided stochastic searches that more effectively cover the policy space. Our approach is based on the value of information, a criterion that provides the optimal trade-off between expected costs and the granularity of the search process. The value of information yields a stochastic routine for choosing actions during learning that can explore the policy space in a coarse to fine manner. We augment this criterion with a state-transition uncertainty factor, which guides the search process into previously unexplored regions of the policy space.