 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrouping-matrix based Graph Pooling with Adaptive Number of Clusters
Paper and Code
Sep 07, 2022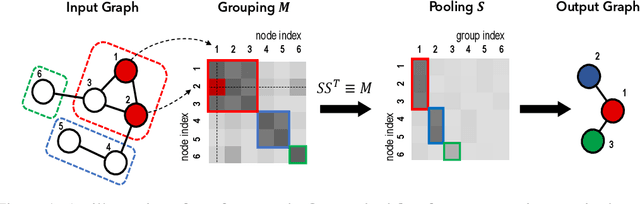
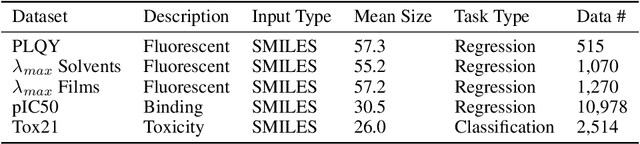
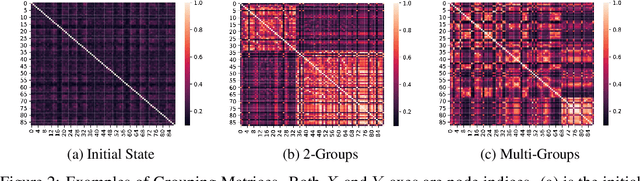
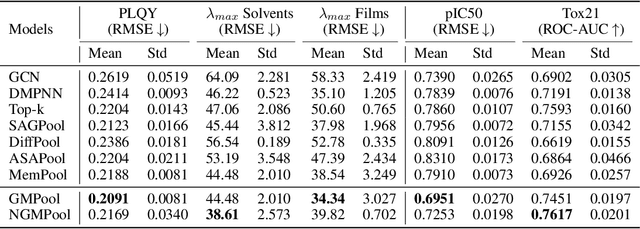
Graph pooling is a crucial operation for encoding hierarchical structures within graphs. Most existing graph pooling approaches formulate the problem as a node clustering task which effectively captures the graph topology. Conventional methods ask users to specify an appropriate number of clusters as a hyperparameter, then assume that all input graphs share the same number of clusters. In inductive settings where the number of clusters can vary, however, the model should be able to represent this variation in its pooling layers in order to learn suitable clusters. Thus we propose GMPool, a novel differentiable graph pooling architecture that automatically determines the appropriate number of clusters based on the input data. The main intuition involves a grouping matrix defined as a quadratic form of the pooling operator, which induces use of binary classification probabilities of pairwise combinations of nodes. GMPool obtains the pooling operator by first computing the grouping matrix, then decomposing it. Extensive evaluations on molecular property prediction tasks demonstrate that our method outperforms conventional methods.